生成AIは、これまでのAIと何が異なるのか――。
エヌビディアが2023年7月19日にオンラインで開催した記者説明会において、テクニカル マーケティング マネージャーの澤井理紀氏はその点から解説を始めた。

エヌビディア テクニカル マーケティング マネージャーの澤井理紀氏
広い意味でのAIのうち、現在最も使われている機械学習技術がディープラーニング(深層学習)であり、生成AIはこの深層学習によるトレーニングデータからパターンと傾向を学習し文脈を理解する。これにより、「問題解決の能力に優れ、かつ、多様な問題解決に応用できる」ことが、従来のAIとの最大の違いだという。
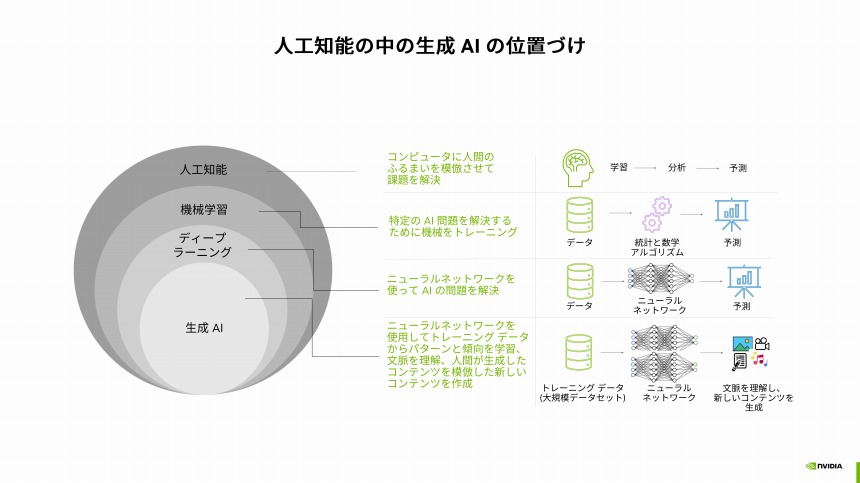
生成AIの位置づけ
この生成AIの核となるのが「基盤モデル」である。AI開発者はこの基盤モデルを自らの目的に最適化する。特に有名なのが、言語を扱う基盤モデルである「大規模言語モデル(LLM)」だ。そのトレーニングはシンプルで、ある単語の次に来る単語を予測するというもの。これを、膨大な量のテキストを使って学習する。
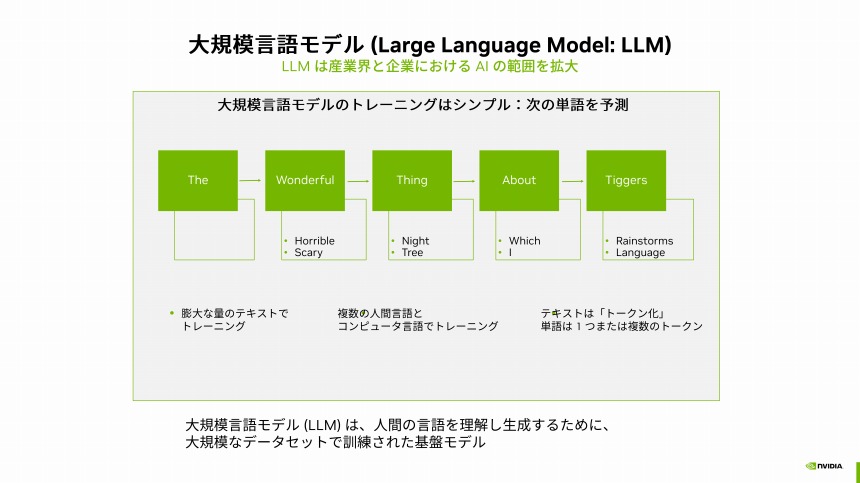
大規模言語モデル(LLM)の概要
LLMは、従来の自然言語処理とは多くの点で異なる。1つが、パラメーター数だ。従来の自然言語処理ではパラメーターが数億であるのに対し、LLMではその数が数十億から数兆にもなる。一方、「LLMはトレーニングデータへのラベル付けが不要で、かつ並列処理の効率も向上したことで、高速なトレーニングと推論が可能になった」(澤井氏)。
ビジネスで使うには「カスタマイズが必須」
LLMをビジネスで活用する場合、必須となるのがカスタマイズだ。
LLMはインターネット上のテキストデータをトレーニングデータとして使っているため、特定ドメインの知識や企業独自のデータを引き出すことは難しい。「コーパス(自然言語の文章を構造化して大規模に集積したデータベース)に含まれない専門知識も持っていないため、自社業務に適用するにはカスタマイズが必要だ」(下図表を参照)。
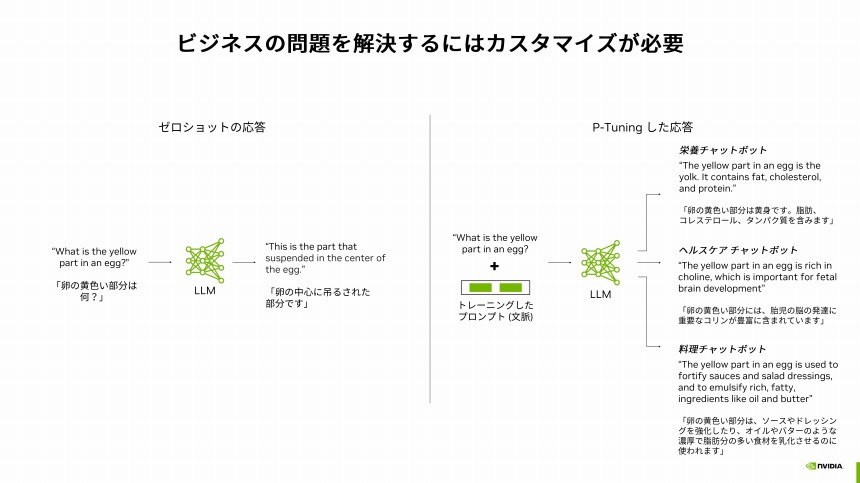
LLMのカスタマイズの例
このカスタマイズの程度により、生成AIの利用法は大きく3つに分けられると澤井氏は話した。一般的な利用法が最小限のカスタマイズによって迅速に市場に投入するケースで、ChatGPTやGoogle Bardのような既存サービスがこれに該当する。もう1つが、「トレーニング済みモデルをファインチューニングして、数週間から数カ月で市場投入する中程度のカスタマイズ」だ。
3つめは、独自の基盤モデルを作る、あるいは大幅なカスタマイズを行う利用法で、これには大規模なインフラと半年以上の開発期間が必要になる。

生成AIの利用方法
このカスタマイズや独自の基盤モデル構築における課題として澤井氏が挙げたのが、次の4つだ。