大規模言語モデル(LLM)の開発コストが高騰する要因の1つに、「取り扱える系列の最大長」を事前に決めておかなければならないというものがある。事前学習時の計算資源の制約から生じるもので、LLMが取り扱う文や音声データの長さなどがこれに当たる。
NTT人間情報研究所 思考処理研究プロジェクト 研究員の岡佑依氏によれば、予め決められた「この長さを超えると、LLMの生成性能は大きく下がる」。これは、Transformer(グーグルが開発した深層学習アーキテクチャ)を使って開発されるすべてのモデルに共通する課題だという。

LLMが取り扱える文の最大長には制限がある
例えば、NTTの独自LLMである「tsuzumi」で1文書(最大文長内)のみの長さを学習した場合、1文書のみの長さを生成させるのには問題がないが、「2文書分の長さの文章を入力したり、生成しようとすると、性能はすごく下がってしまう」(岡氏)。性能を維持するには、多くの計算資源を使って、2文書分の長さで再学習しなければならない。
単語の位置を表現する「位置符号化」に着目
現在、LLMの再学習には数千万円規模のコストがかかるという。もし、予め決められた最大長を超える生成が可能になれば、生成AIの開発コストは大きく削減され、利用料の低減などのかたちで私たちユーザーも恩恵を受ける可能性がある。

LLMにおける長文対応のイメージ
NTTは2025年4月24日、この課題を解決する新技術を開発したと発表した。LLMで最大系列長を超える長文を扱えるようにする技術だ。
岡氏らの研究チームが着目したのは、LLM内部で単語の位置を表現する「位置符号化」と呼ばれる仕組みだ。位置符号化には、文の先頭からの各単語の位置を表現する「絶対位置」と、文を構成する各単語同士の相対的な位置を表現する「相対位置」の2つの手法が使われている。
前者は計算が高速なため多くのLLMで使われているが、文の先頭からの絶対位置を採用しているため、最大系列長より長い文を生成すると性能が下がってしまう。対して、相対位置は最大系列長より長い文を生成しても性能は下がらないものの、遠い依存関係にある単語の情報を取得できない、絶対位置と比べて短い文の生成性能が低いといった点が課題であるという。
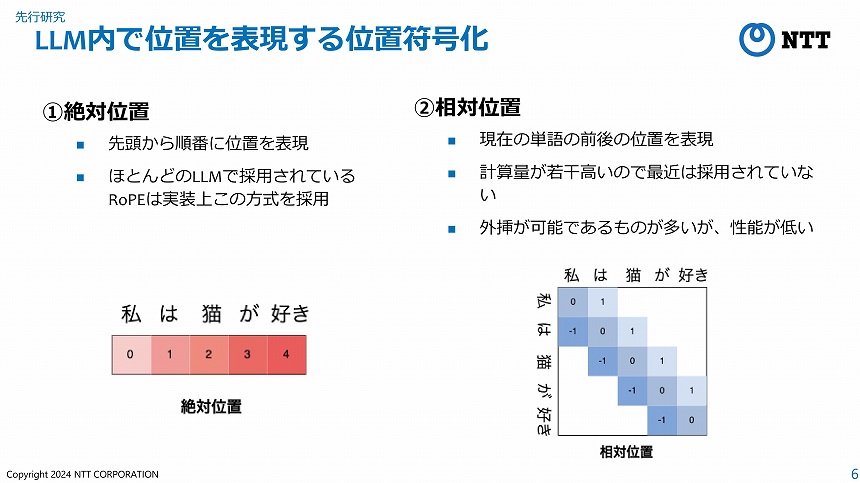
絶対位置と相対位置
NTTは、こうした双方の弱点を補う「ウェーブレット位置符号化」技術を開発。評価実験において、メタのLlamaやグーグルのgemmaなどが採用している位置符号化であるRoPE等と比べて高い性能を発揮することを確認した。