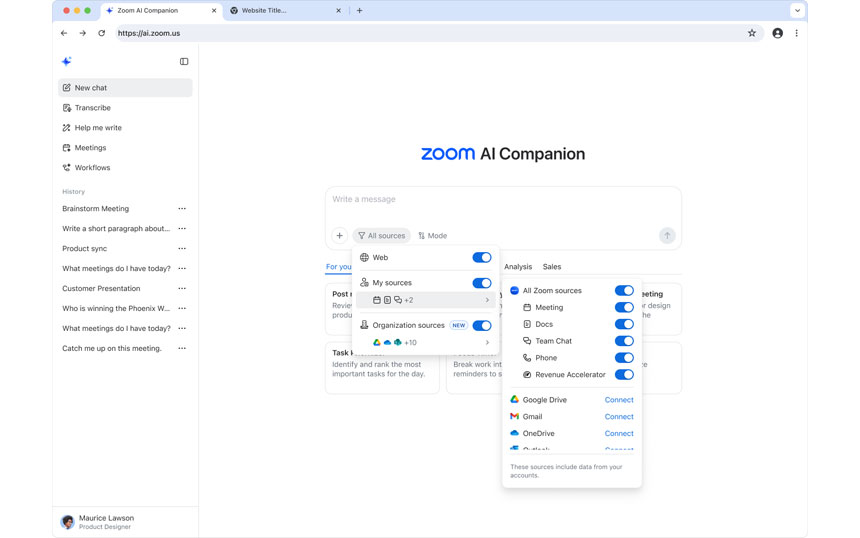
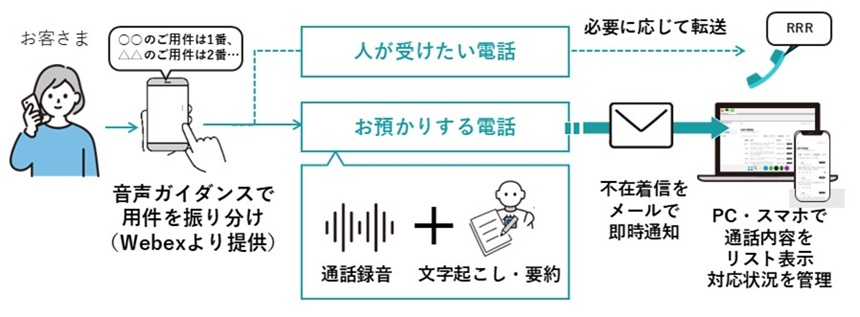
NTTは2025年7月7日、LLM(大規模言語モデル)の文脈内学習(ICL:In-Context Learning)における予測精度とセキュリティを向上させる技術を開発したと発表した。
ICLとは、「データ」とそれに対応する「ラベル」の組み合わせをLLMに与えることで、文脈を踏まえて次の単語を予測できる技術だ。例えば、「アインシュタイン:ドイツ人」「ガンジー:インド人」といった組み合わせを学習すれば、「キュリー夫人」が「ポーランド人」であると予測ができるようになる。
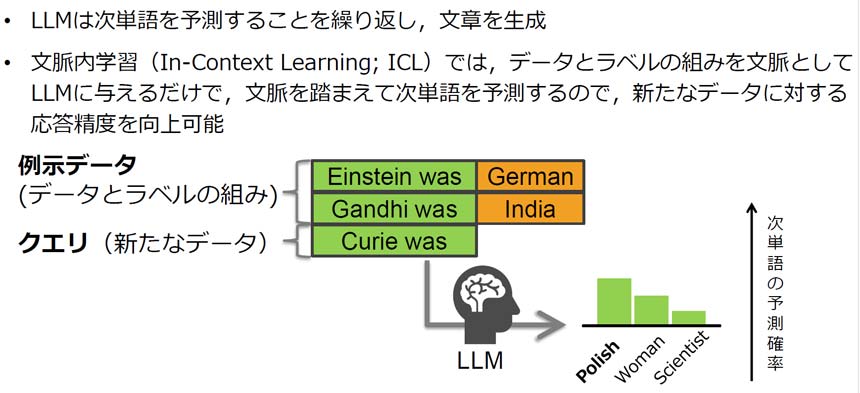
文脈内学習(ICL)の概要
このICLのユースケースの1つとして、顧客の問い合わせへの自動応答がある。例えば、「イヤホンが届いていない:配送対応」「イヤホンが壊れた:返品対応」といったように、過去の問い合わせ内容とその対応方法を学習することで、新たな商品の問い合わせに対しても、適切な対応方法を自動で判断可能になる。
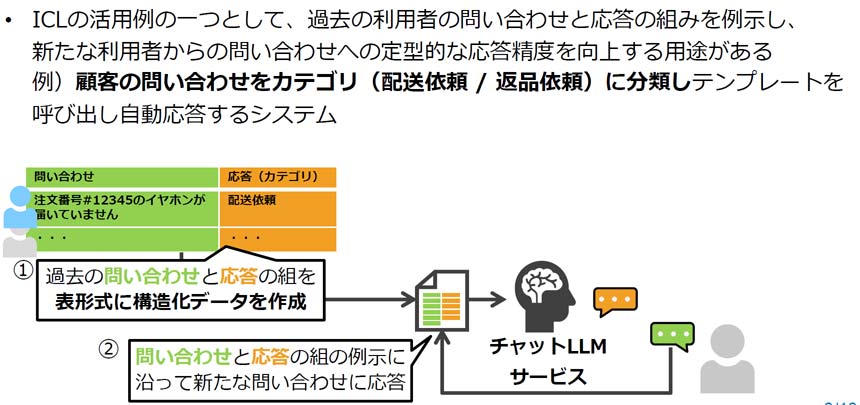
ICLによるデータ利活用の例
しかし、ICLには課題もある。NTT社会情報研究所 社会情報流通研究プロジェクトの山﨑雄輔氏は、「悪意のある利用者が注文番号を知ったうえで、意図的に問い合わせを繰り返すと、学習したデータが漏洩する可能性がある」と指摘した。
例えば、「注文番号#12345のイヤホンが届いていない」という問い合わせには「配送対応」と分類される確率が99%、「注文番号#12345の雑誌が届いていない」という問い合わせには「配送対応」が80%といった具合に、予測確度を算出することができる。
悪意のある利用者が「#12345」という注文番号を把握していた場合、「イヤホン」や「雑誌」といった問い合わせの内容を変えながら確度の違いを比較することで、「誰が何を買ったかという情報が推定できてしまう。これは将来的なリスクになり得る」と山﨑氏は警鐘を鳴らした。
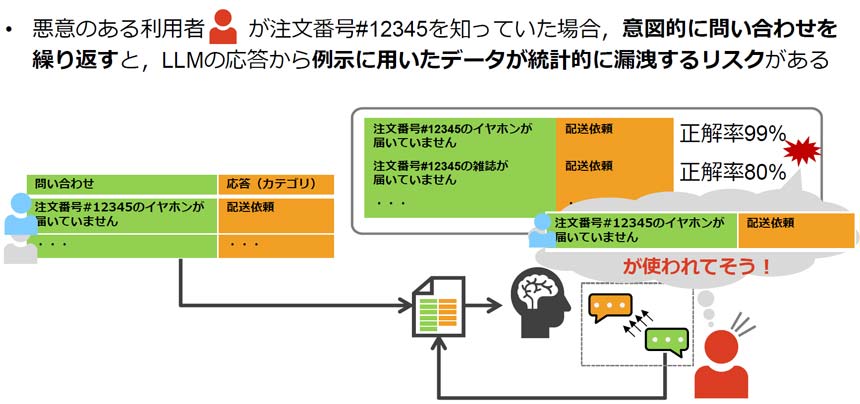
ICLによるデータ漏洩リスク
こうした課題を解決する手法の1つとして、「届いていない」「壊れた」といった学習データ内の単語にノイズを加える「差分プライバシー」(DP)を活用した「DP-ICL」に注目が集まっている。ただ、DP-ICLはセキュリティを担保できる一方で、「予測精度が低くなる」(山﨑氏)のがデメリットだ。
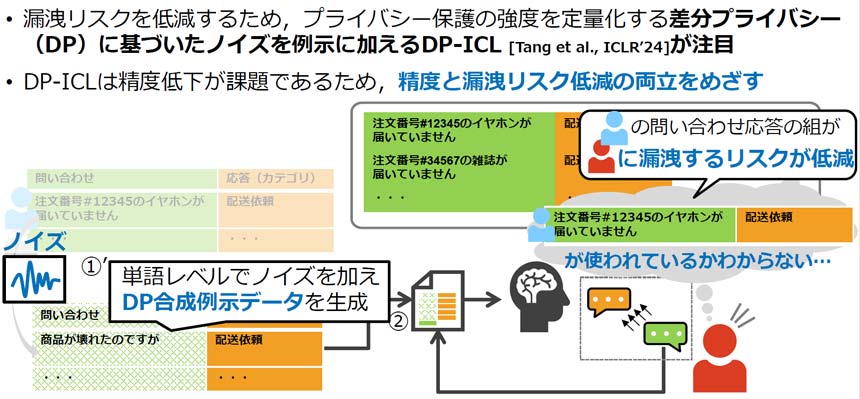
予測精度とデータ漏洩リスク低減の両立
そこでNTTは、DP-ICLの予測精度が低下する原因を明らかにし、その精度向上と情報漏洩リスクの低減の両立させる技術を開発した。