GPU間通信に専用リンク
「1つのネットワークで複数の要件を満たすことは、もう難しい。ストレージ用、インターネットとの通信用、そしてGPU同士のインターコネクト用と、用途別にネットワークを分けて作らなければならなくなったことが今までとの違いだ。しかも、その種類はどんどん増えていく」
2023年春に日本で初めてNVIDIA DGX H100を導入し、社内向けの生成AI基盤「ML Platform」を構築したサイバーエージェント。同基盤のネットワーク構築・運用を担うCIU Platform Div ネットワークリーダーの内田泰広氏は、データセンター(DC)ネットワークの変化についてそう語る。

(左から)サイバーエージェント グループIT推進本部 CIU(CyberAgent group Infrastructure Unit) Platform Div NWチームリーダー 内田泰広氏、同 NWエンジニア 小障子尚太朗氏
生成AI基盤においては、複数のGPUサーバーを使った並列分散学習を行うための専用ネットワークが必要になる。かつては1台のGPUサーバーで機械学習を行っていたが、LLM(大規模言語モデル)の学習には、GPUサーバー1台のメモリでは処理が追いつかず、複数台のGPUサーバー(GPUクラスター)で並列分散学習できる環境が不可欠となった。学習時間を短縮するには、並列数を増やすしかない。
このGPU同士の通信に求められる要件は、これまでのDCネットワークとは全く異なる。広帯域かつ低遅延であることに加えて、最も重要なのが「ロスレス」であることだ。分散学習では、複数のGPUが一気に大量のデータを出し、それを同期させてからまた学習を続けるという動作を繰り返す。輻輳が起きてパケットが落ちると処理はやり直し。しかも通信している間は、GPUはアイドル状態のため処理はまったく進まない。ロス/再送が起きれば、GPUクラスター全体のパフォーマンスが落ちる。
そのため、この通信はストレージやインターネット向けの通信と同居できない。サイバーエージェントが今回構築したML Platformは図表1のように要件が異なる5種類のネットワークで構成。②および③がGPU間通信用のインターコネクトだ。
複数のGPU間でデータをやり取りする場合、CPU/共有メモリを介さずGPUメモリ同士で直接転送することで高速化できる。サーバー内でこれを行うためのエヌビディア独自規格がNVLinkだ(図表1の②)。H100のNVLink4の転送速度は900GB/秒、7.2Tbpsに相当するほど高速である。
図表1 並列分散処理するためのネットワーク構成
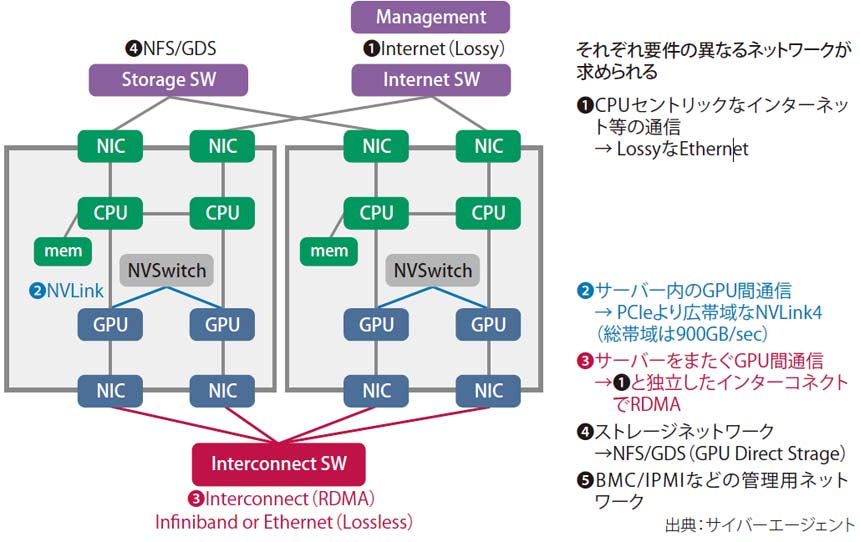
InfiniBandかイーサネットか?
GPUサーバー間の通信(図表1の③)でも同様に、GPUメモリ間で直接通信するRDMA(Remote Direct Memory Access)を使う。RDMAはパケットロスのないネットワークを前提としたプロトコルで、そのための専用規格がInfiniBandだ。非常に高い信頼性・可用性が求められるサーバークラスター用に設計された通信規格である。スパコンやHPC(ハイパフォーマンス・コンピューティング)の分野で広く使われているが、一般的なネットワークエンジニアには馴染みのない技術だ。
生成AI基盤においては、GPU間インターコネクトをInfiniBandで作るか、それとも慣れ親しんだイーサネットでRDMAを実現するRoCE(RDMA over Converged Ethernet)v2を使うかの2つの選択肢がある。
サイバーエージェントが選んだのは後者だ。理由は「イーサネットの資産を使えること」(内田氏)。Platform Div ネットワークエンジニアの小障子尚太朗氏も、「やっぱりイーサネットは安心感がある。当時のネットワーク担当が(内田氏と自身の)2名だったこともあり、運用経験があるイーサネットを選んだ」と振り返る。
2023年6月から運用を開始したML Platformは80基のGPUを使用。社内の複数ユーザー、システム/アプリで共用している。InfiniBandはその仕組み上、マルチテナント化ができないが、これもイーサネット採用の決め手の1つだったという。