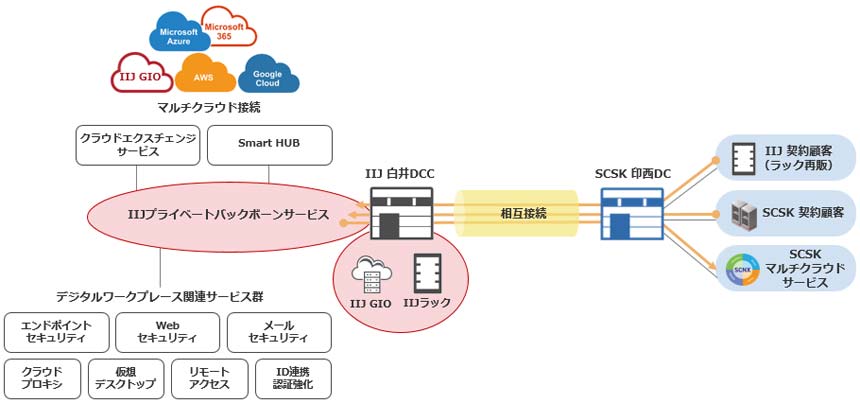
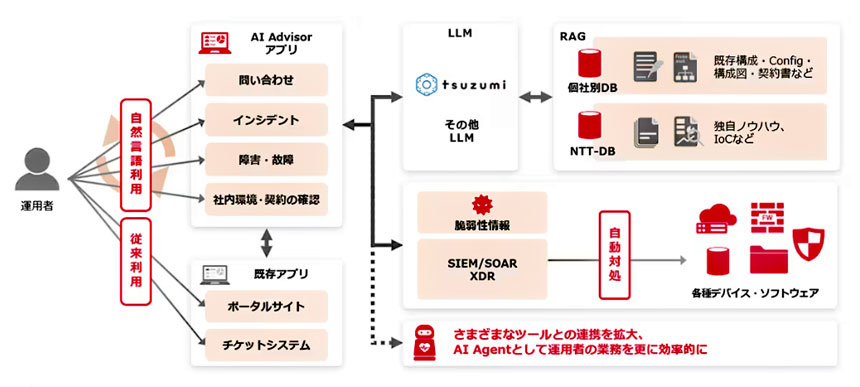
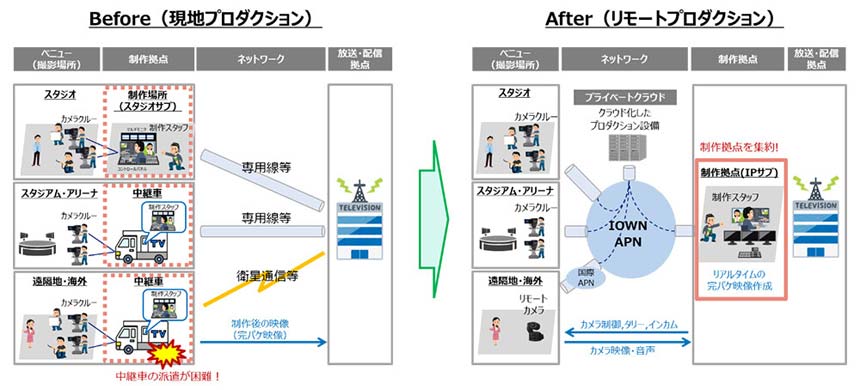
「AIを制するものは市場を制す」――。こう言っても過言ではない時代が到来しつつある。多くの企業が新しい生成AIモデルを開発し、新たなAIサービスを展開しようとしている。それには一にも二にも、より大規模で高速な計算能力が必要だ。
もちろん技術の進化に伴い、この数十年でより多くのコンピュータリソースが安価に利用できる環境は整ってきた。だが生成AIの登場は、文字通り桁違いの高速な処理能力を必要としている。主な演算を行うGPUはもちろん、それらをつなぐネットワークにも従来以上の「性能」が求められる。
ここでいう「性能」とは、単なる帯域や通信速度を意味しない。低遅延でロスレスなネットワークの必要性がこれまで以上に高まっているが、それだけでも不十分だ。AIモデルの計算というワークロードの特性に応じてエンドツーエンドで最適化されたネットワークが求められている。
広帯域、ロスレスだけでは不十分なAI時代のネットワーク
改めて言うまでもなく、AIはこれまでにないイノベーションを生み出すものとして期待され、多くの企業が開発に力を注いでいる。その基盤として注目されているのがクラウド環境だ。
ただ、これまでのクラウド環境でも一定程度の規模のAIモデルならば対応可能だが、より大規模な生成AIの計算に十分かといえば疑問が残ると、NVIDIA シニアソリューションアーキテクトの野田孝氏は指摘する。
そもそもAIモデル計算とクラウドサービスとでは、処理の性質が大きく異なる。「一般のクラウドサービスでは何千人、何万人のユーザーが同時にアクセスし、比較的小規模な計算を行います。一方AIの処理では、より少数のユーザーが極めて大きな計算を、超高速に実行する形となります」(野田氏)

NVIDIA シニアソリューションアーキテクト 野田孝氏
また、クラウドサービスは、1つひとつの処理が疎結合で個々のサーバーで独立して行われ、その結果を順に受け渡していく形で実現されるのに対し、生成AIの分散学習は、多数の異なるGPUサーバー間で協調して動作する並列分散処理が基本となる。このため、ある特定のノードの遅延やパケットロスが全体の性能に大きな影響を及ぼす可能性がある。つまり、現行のネットワークではAI計算のボトルネックとなる恐れがあるのだ。
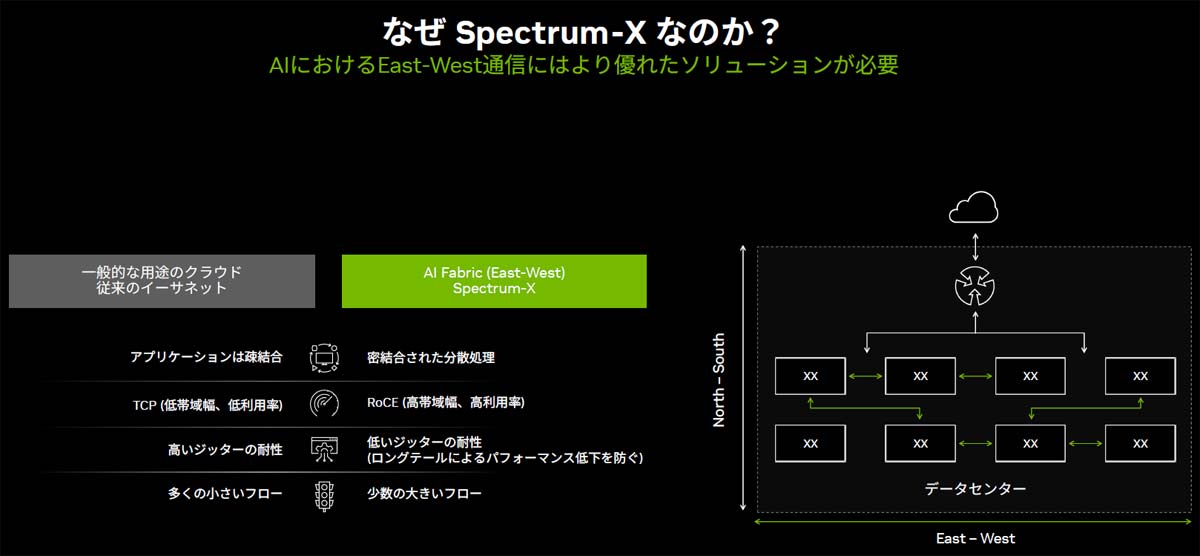
一般的なクラウドサービスとAIワークロードの特性の違い
こうした課題を踏まえ、ネットワーク技術も進化している。その代表例が、InfiniBandのRDMA(Remote Direct Memory Access)をイーサネットに取り込んだ「RDMA over Converged Ethernet」(RoCE)だ。RDMAは、CPUを介さずにデータを直接メモリからメモリへ転送する技術であり、これにより大幅なレイテンシーの低減と高いスループットが実現される。RoCEはこの技術をイーサネット上で実現するものだ。
このような進化は歓迎されるべきだが、それでも大規模生成AIの計算を担うのに十分とは言えない。そこで「NVIDIAでは、データセンター自体がコンピューティングプラットフォームとなっていく『AIファクトリー』という構想を掲げています。AI計算をより高速に、効率よく実現するには、ネットワークだけではなくインフラ全体で最適化を図っていく必要があります」(野田氏)。
真の意味でエンドツーエンドでの最適化を実現するSpectrum-X
ネットワークもAIインフラの一部と捉え、NVIDIAが大規模生成AI計算プラットフォーム向けに開発したソリューションが「Spectrum-X」だ。標準のイーサネット技術をベースに、大規模生成AIという、これまでとは特性が大きく異なるワークロードを効率よく実行するための拡張や最適化が施されている。
最大の特徴は、スイッチ間のネットワーク通信だけを最適化するのではなく、サーバー側に搭載される「BuleField-3 SuperNIC」と連携することによって、エンドツーエンドで最適化を図っていることだ。BlueField-3は高度なネットワーク機能を備えたDPU(データ処理ユニット)ベースの特別なNICである。Spectrum-Xを構成するSpectrum-4スイッチとBlueField-3 SuperNICの間は、最大400Gbpsで接続される。

標準イーサネットをベースに、AIワークロードに最適化した機能を拡張したSpectrum-X
Spectrum-Xは前述のRoCEに最適化されており、パケットドロップが起こりにくいロスレスイーサネットを実現するだけでなく、BlueField-3 SuperNICを搭載したエンドポイント間でラウンドトリップタイムを測定し、リアルタイムにネットワークの輻輳ポイントを検出することが可能だ。その数値に基づいて送信レートを動的に調整する輻輳制御機能も備えている。
さらに、「アダプティブルーティング」によるトラフィックの負荷分散も実現している。複数のネットワーク経路にまたがり、キューの占有状況やポートの使用率などに基づいて転送パスを動的に選択する仕組みで、ネットワーク経路をしっかり使い切る。この結果、RDMAのデータ通信性能は1.6倍に、有効帯域幅は標準的な60%から95%に高めることが可能だ。
しかも、Spectrum-4スイッチとBuleField-3 SuperNICの間で帯域や負荷分散状況などを把握・管理できているため、処理時間の揺らぎ、いわゆるジッターにも高い耐性を備えている。「All-Reduce」のようにn:1で通信を行う極端な集約処理が発生する場合、通常のイーサネットではデータ衝突が頻繁に発生して性能が安定しないが、Spectrum-Xではばらつきを抑えることができる。第三者が計算を始めて突発的にネットワークに多くのトラフィックが流れ込むような場合でも、影響を最小限に抑えることが可能だ。
こうしたAIワークロードの特性に最適化した機能は、スイッチというネットワーク基盤単体だけでは実現が困難だ。NIC、その先につながるGPUやDPUといったハードウェア、さらにはその上で動作するCUDAをはじめとするソフトウェア群やアプリケーションフレームワークに至るまで、NVIDIAのフルスタックソリューションによって初めて実現されるものであり、マルチテナントのAIクラウド環境で最高の有効帯域を実現し、より高速なAI計算が可能になる。
しかも一連の機能は、プレゼン資料上だけの絵に描いた餅ではない。NVIDIAでは現在、イスラエルのデータセンターに、256台のNVIDIA HGXサーバーから構成されるAIスーパーコンピューター「Israel-1」を実際に構築しており、80台以上のSpectrum-4スイッチと2560枚のBlueField-3 SuperNICを使用した、8エクサFLOPSというパフォーマンスを実現できるスーパーコンピューターになる見込みだ。Spectrum-Xは、フルスタックをカバーできる、エンドツーエンドで実証されたテクノロジーなのだ。

イスラエルで最もパワフルなスーパーコンピューター、Israel-1 Spectrum-X 生成AIクラウド
NVIDIAはこのSpectrum-Xを、個別の製品として提供するのではなく、OEMベンダーが提供するサーバーも含め、最先端のAIモデルでベンチマークテストやチューニングを随時実施した上で実証済みのリファレンスデザインとともに提供する。これにより「想定した性能が出ない」といった落とし穴に陥ることなく、最短で最高速のAI環境が導入できる。
この結果、投資対効果も非常に高くなる。「拡張されたネットワークパフォーマンスによってGPUの稼働効率にも貢献し、計算インフラとしてより高い価値を提供できます」(野田氏)
大規模生成AIの計算を支える「生成AIクラウド」を実現
このようにSpectrum-Xによって、既存のクラウド環境ではボトルネックとなっていたネットワークの課題を解決でき、大規模生成AIの計算を支える「生成AIクラウド」が実現できる。
ただ、世の中の生成AIへのニーズはとどまることを知らない。市場の先頭を行くユーザーは、生成AIクラウドを超える規模のクラスタコンピューティングによって、さらに高速な計算を実現するAIファクトリーの実現をにらんでいる。この規模の計算を支えるネットワークインフラとしては、やはりInfiniBandに一日の長がある。
NVIDIAではこうした市場向けに「Quantum InfiniBandプラットフォーム」を提供してきた。そもそもSpectrum-Xに搭載されているアダプティブルーティングや輻輳制御といった機能は、元々Quantum InfiniBandで開発・実装されてきた技術をベースにしたものだ。
さらに、InfiniBand自体の性能向上も継続的に図られている。一例が、階層的な集合計算の中で、NICを活用して負荷をオフロードし、ネットワークを通過するデータ量を減少させて全体のパフォーマンスを向上させる「SHARP」(Scalable Hierarchical Aggregation and Reduction Protocol)だ。レイテンシーを抑え、実行時間を15%以上短縮させることができ、「貴重なCPUやGPUのリソースを通信処理に使用するのではなく、計算のために解放できるといった大きなメリットがあります」(野田氏)。
コンピューティングの歴史は、常にパフォーマンスとの戦いだった。AIはその戦いを、さらに極端な形で繰り広げるものといえる。
そんな中、これまでのITの世界の延長で、サーバーはサーバー、ネットワークはネットワークで個別に性能拡張に取り組んでいっても頭打ちは避けられない。「処理能力が足りないから、GPUを買い足そう」と投資しても思ったような性能が出ないのは誰にとっても不幸なことだ。視野を広げ、アーキテクチャ全体の最適化という観点から検討することが重要だ。
AI計算を支えるネットワークは広帯域・低遅延は当たり前。NVIDIAはGPUの観点だけでなく、AIワークロードに最適化され、しかも簡素に導入できるネットワークソリューションをフルスタックで提供することで、ネットワークパフォーマンスの限界を押し広げ、AIの世界を後押ししていく。
<お問い合わせ先>
エヌビディア合同会社
お問い合わせ窓口:https://nvj-inquiry.jp/