「推論は小さなエッジで」が通用しない時代が来る
この違いを見れば、誰もがリーズニングを求めるだろう。だが、AIサービスとして具現化するには高い壁が立ちはだかる。計算量の爆発的増加だ。
図表1のリーズニングモデルの回答は約300トークンだが、それを得るために思考を巡らす過程で6000超のトークンが生成された。インファレンスの20倍以上の計算が裏で動いていることになる。何十・何百万件もの質問に応えるには膨大な計算が必要だ。どれほどのコンピューティング/ネットワークリソースを用意すれば、このリーズニングモデルを社会実装できるのか。
これまでは、AI推論のリソースは、AI学習のそれと比べて小さくてよいと考えられてきた。「推論はあまりGPUを使わないから、エッジで簡単にできると。でも、みながリーズニングを欲しがると、そんな見通しは吹っ飛んでしまう」と愛甲氏。私たちは早くも、AIインフラのあり方を考え直さなければならない時期に来ている。
では、エヌビディアはリーズニング時代のAIインフラをどう描いているのか。鍵は、推論処理の効率化だ。
推論処理は前処理(Prefill)と、出力生成(Decode)の2段階に分けられる。Prefillは、入力されたデータに基づいて関連しそうな情報を計算して詰め込む計算集約型の処理。GPUをフル回転させる演算処理が中心だ。Decodeは、計算結果から当てはまるものを探し出して出力する。データの検索と出力、つまりメモリアクセスを主にする。
両方を同じGPU上で連続して行うと、非効率になる可能性が高い。例えば、Prefill実行中はメモリ帯域を遊ばせることになり、リソースを100%使い切れない。複数ユーザーからのリクエストに効率よく応えるには、この無駄を極力排除しなければならない。
NVIDIA DynamoでGPU割り当てを最適化
そこでエヌビディアが提案しているのが、分離型推論処理だ。GPUリソースを分割し、Prefillには高性能なGPUを、Decodeにはメモリ帯域を適切に割り当てることで利用効率を高める。
これを実現するのが、オープンソースの推論ソフトウェア「NVIDIA Dynamo」だ。上記のリソース分離/最適化を行うため、リクエストに応じてGPUの割当を自動調整するプランニング機能や、効率的にルーティングするSmart Router、高速・低遅延転送、KVキャッシュのオフロード機能を備える。
推論処理を設計し直したDynamoを利用することで、大規模なリーズニングモデルで目覚ましい効果が得られるという。DeepSeekモデルではスループットが最大30倍に、Llamaモデルでは最大2.5倍に向上。1秒あたりのトークン数や応答性が大きく改善する(図表2)。同じハードウェアで倍以上のユーザーを相手にできるだけでも特大の影響があるが、場合によっては数十倍もの性能アップが見込めるというのだ。電力消費の抑制にもつながり、データセンター全体のTCO削減にも貢献できる。
図表2 強化されたAIファクトリは利益に貢献する
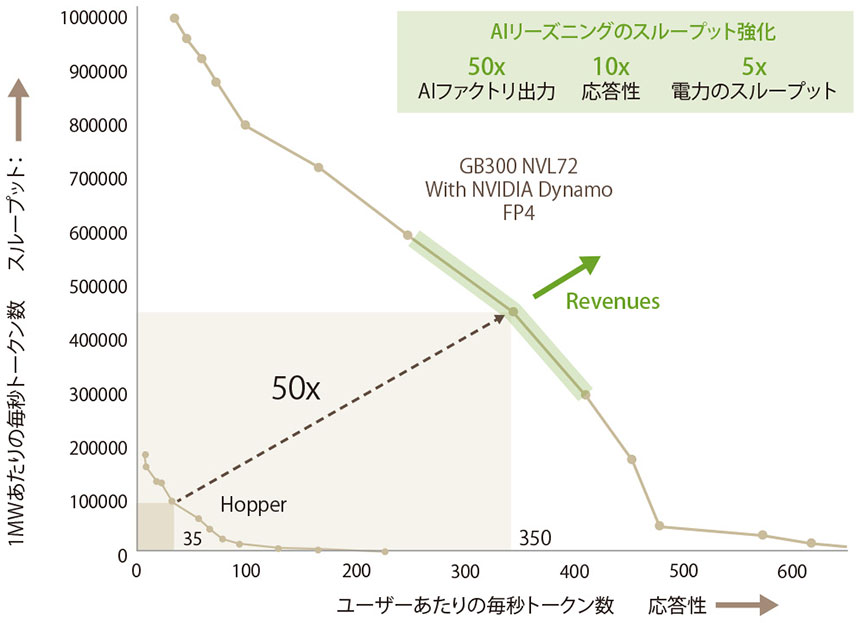
今後は、リーズニングの需要を見据えたAIインフラ投資が必要となるが、分散推論のコンセプトとDynamoの機能は、その収益化において不可欠なコンポーネントとなるだろう。
そしてもう1つ、忘れてならないのがネットワークの重要性だ。リーズニングには、裏側で何千・何万のトークンを生成し、データをやり取りするための太い道路が必要だ。しかも、「AIという特別なワークロードに合わせたコンピューティング能力が必要なように、ネットワークも適正にルーティングさせないと非効率になる」と、シニア マーケティングマネージャの矢嶋哲郎氏は話す。Smart Router等のDynamoの機能と組み合わせて、高速データ転送用ネットワークを用意しなければならない。
この点でもエヌビディアはSpectrum-XやInfiniBandなどのネットワーク製品に加えて、光電融合技術を取り入れたCPO(Co-Packaged-Optics)を業界に先駆けて市場投入するなど、AIインフラのネットワーク面での進化も支えている。
<お問い合わせ先>
エヌビディア合同会社
お問い合わせ窓口:https://nvj-inquiry.jp/