目次
「AIの通信」を理解する
生成AIの登場と普及は、今や社会・経済基盤となったデータセンターに大変革をもたらしている。GPUの大量導入と稼働の影響を受けるのは電力や冷却設備だけに留まらない。ネットワークも変化を強いられる。
AI時代のデータセンターインフラは、GPUセントリックな形態へとシフトしていく。データセンターネットワークもそれとともに、構造と使用する技術が変わる。AI処理を高速化するための通信「AIインターコネクト」は、単純にデータをやり取りしていた従来のデータセンターネットワークとは、その役割を大きく変える。
AIインターコネクトの主役は、AI関連処理の担い手であるGPU間の通信だ。GPUチップ間、GPUサーバー間、そしてラック間/データセンター間でそれぞれ異なる技術が使われるが、求められる要件は基本的に変わらない。
通信技術の進化の主軸は、もちろん性能の向上だ。データセンターネットワークはこれまで、増加するトラフィックをさばくために高速・大容量化が進んできたが、GPU間通信ではこれに加えて、低遅延であることと、パケットドロップを起こさない「ロスレス」であることがいっそう重要になる。
これは、AIの学習で発生する通信が、従来のデータセンター内で行われるそれと異なるためだ。
AIの学習では、大量のデータを多数のGPUで分散処理し、結果を集めてまた分散処理するという動作を繰り返す。このデータ転送を高速化するのが、DMA(Direct MemoryAccess)だ。OSやCPU、メインメモリーを介さず、GPUメモリー間で直接アクセスする技術である(図表1)。
図表1 GPUメモリ間のデータ転送
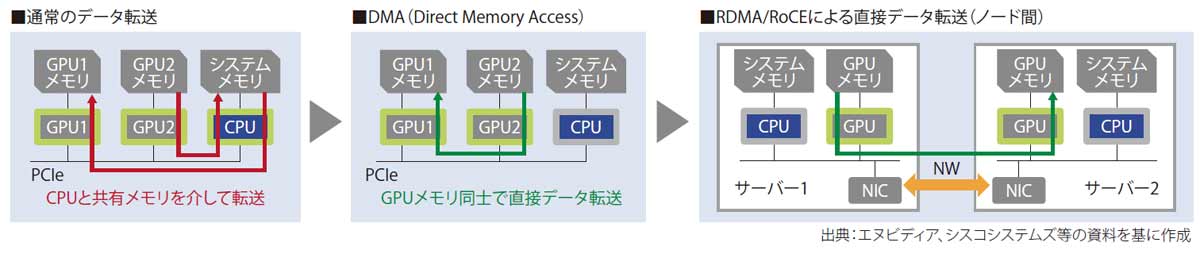
この並列分散学習において、GPU間で通信している間は、GPUの処理は止まる。したがって、通信遅延は少なければ少ないほど、高価なGPUサーバーを効率的に使える。最悪なのはパケットロスが発生することで、再送処理の間、残りのGPUはその完了を待つ。最も遅い1台に、残り全てのGPUが合わせることになる。
だが、従来のデータセンターネットワークはそもそも、こんな処理を想定していない。そのため、外部からデータを取り込んだり、CPUやGPUが処理した結果を外部に送る「フロントエンドネットワーク」やストレージ用のネットワークとは別に、GPU間通信に特化した「バックエンドネットワーク」を作る必要が出てきた。GPUを効率的に動かすため、次々と新たな技術・ソリューションが登場してきている。
ここで注目されるのが、GPUチップ/サーバー間接続技術のオープン化だ。AI開発やHPC(ハイパフォマンスコンピューティング)の領域ではこれまで、GPU市場で一強状態のエヌビディアが提供するインターコネクト技術が主に使われてきた。生成AI開発の裾野が広がり、需要が爆発的に増加したことで、これに匹敵する性能・機能を持つ業界標準技術の開発が進んでいる。
以下、(1)GPU間接続、(2)GPUサーバー間接続、(3)データセンター間接続(DCI)の各領域について技術トレンドを見ていく。