大規模言語モデル(LLM)の開発競争が世界中で繰り広げられているが、最大のトレンドと言えば、やはり“大規模化”だろう。それとともに開発コストはうなぎ登り。2020年のGPT-3 175B(パラメータ数が1750億個)は1回の学習コストが約5億円だったのに対し、最新のGPT-4はパラメーター数が1兆個、学習コストは150から200億円に達すると推定されている。
同時に、学習に費やされるエネルギーも膨大なものとなる。GPT-3では1回の学習に約1300MWh(Wh:電力量)が必要とする調査データがある。これは原発1基分の1000MWhを超える電力量だ。
今や、LLM開発には数百から数千基ものGPUを使うのが当たり前になりつつある。学習にかかるコストと消費電力の増加をどう抑えるかは、AIの社会実装を進めるうえで大きな課題だ。そして、これは学習のみならずAI推論の実行環境を広げるうえでも課題となる。

tsuzumiの開発、ユースケース開拓などについて講演する
NTT 執行役員 研究企画部門長の木下真吾氏
軽量でも「性能は世界トップクラス」
こうした大規模化の潮流とは真逆の方向性で進化を目指しているのが、NTTの独自開発LLM「tsuzumi」だ。すでに商用化している軽量版「tsuzumi-7bモデル」のパラメーターサイズは70億。現在評価中の“中型版”tsuzumi-13bでもその倍に満たない。
2024年11月21日に開催された「NTT R&Dフォーラム2024」のメディア向け内覧会で基調講演に登壇したNTT 執行役員 研究企画部門長の木下真吾氏は、このtsuzumiについて、「GPU 1つで動き、専門知識を獲得させやすい。マルチモーダルで図表読解にも対応していて、性能は世界トップクラス。特に日本語に強い」と強みをアピール。加えて、オープンソースのLLMをベースに開発するケースが増えているなか、「基盤モデルをイチからスクラッチ開発している」点も特徴に挙げた。

tsuzumiのバージョンアップの概要(13bはベータ版)
tsuzumi-7bモデルは商用開始時点のv1.0から、現在はv1.2へと進化している。対応言語がv1.0の日本語・英語から、v1.2ではドイツ語・イタリア語・スペイン語が追加。マルチモーダル対応によって視覚読解の能力を獲得し、RAG(検索拡張生成)の強化も図っている。
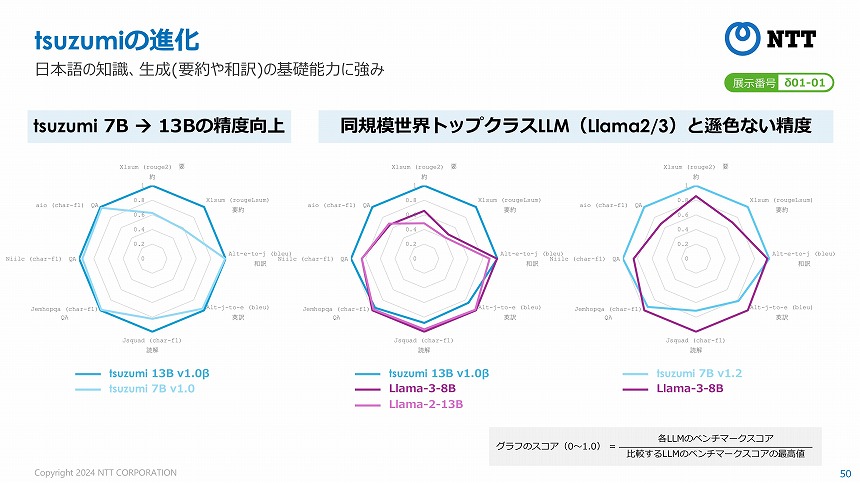
tsuzumi-13bと7b、Llama-2/3との比較
そして、ベータ版のtsuzumi-13bモデルは、7bに比べて要約や読解の精度が向上(上図表)。パラメーターサイズが同規模のLLM「Llama-2・3」と比べても遜色ない性能を持っているという。木下氏は、「サイズがすべてではない。サイズ競争なら、金があるところが勝つ。もっと効率的で軽量なアプローチで」今後も開発を進める方針を強調した。