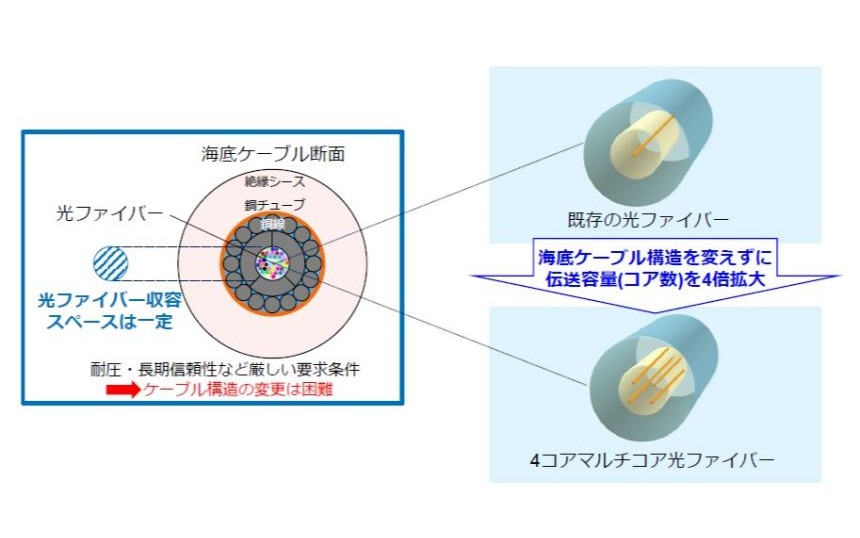
目次
AIデータセンターネットワークの課題
イーサネットで「ロスレス」ネットワークを作る──。
生成AIが台頭してきた今、データセンター(DC)ネットワークの構築・運用において最も重要なテーマとなりつつあるのが、これだ。従来のDCネットワークのアーキテクチャでは、生成AI基盤を支えるネットワークを作りたいというニーズに太刀打ちできないから、というのがその理由である。
問題は、LLM(大規模言語モデル)等の学習に使われるGPUサーバーの運用効率が、ネットワークの性能に大きく左右されるという点にある。「今まで通りのDCネットワークを作るのでは、GPUの性能を活かしきれない」と語るのは、ネットワンシステムズ 東日本第3事業本部 エンタープライズ第3技術部 第2チーム マネージャーの藤井拓良氏だ。
生成AIを開発する企業や、そのためのインフラを提供するDC/クラウド事業者らにとって、これは由々しき問題だ。
GPUサーバーは非常に高額なうえ、世界的に需要が急増していて取り合いの状況にもある。そんななか、ネットワークがボトルネックとなって、せっかく購入したGPUのパフォーマンスが毀損されることなど許されない。投資対効果の観点はもちろん、今や企業競争力を左右するとも言われる生成AI開発に遅れが生じるような事態は何としても避けなければならないのだ。
この問題を解決する鍵が「ロスレス」、パケットロスが発生しない高性能なネットワークを作ることにある。
なぜ「ロスレス」なのか 高価なGPUをサボらせない!!
生成AIの開発においては、複数のGPUサーバーを使った並列分散学習を行うための専用ネットワークが必要になる。
基盤モデルの学習では膨大なデータを処理するため、何十台・何百台、時には何千台ものGPUサーバーをつないだGPUクラスターで並列分散処理を行う。このGPU間の通信は、パケットロスが許容される一般的な通信とは要件が大きく異なるので、図表1のように専用ネットワークを構築する。
図表1 AI/MLネットワークの構成と要件
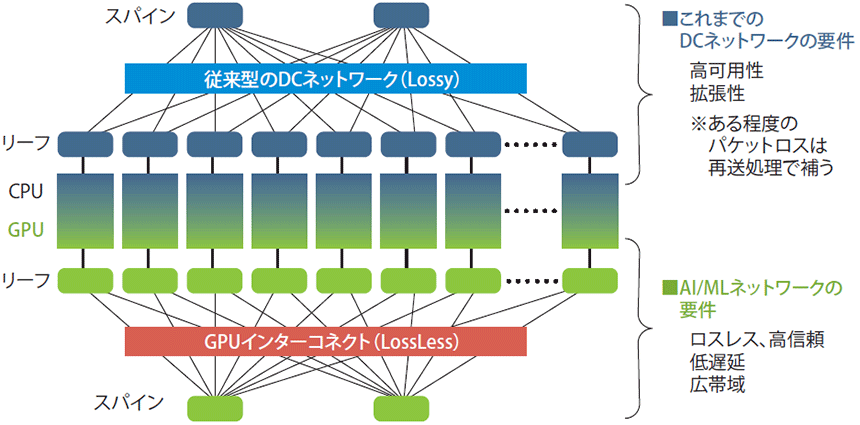
既存ネットワークとの違いは大きく3つ。藤井氏と同チームでシニアスタッフを務める平瀬健一氏によれば、「広帯域であること、低遅延であること、そしてパケットロスが一切ないことが必須条件だ」。
GPUサーバーのNIC(ネットワークインターフェースカード)は今や200GbE、400GbEと広帯域化しており、並列分散学習では、GPUインターコネクトに大容量のデータが一気に流れる。これをさばく容量が必要となるが、400GbE対応のDCスイッチがすでに普及しており、今年後半には800GbE製品も登場する。この点は比較的容易に対応できよう。