データポイズニングに注意
生成AIのセキュリティリスクは、フィッシングメールやマルウェアだけに留まらない。「大規模言語モデル(LLM)を用いたサービス開発にも、セキュリティリスクが潜んでいる」とChillStack 代表取締役CEOの伊東道明氏は警鐘を鳴らす。

ChillStack 代表取締役CEO 伊東道明氏
伊東氏によると、LLMを用いたサービス開発パターンには、「ゼロからの開発」「公開済LLMを用いたファインチューニング」「公開済LLMを用いたサービスの利用」の3パターンがある(図表2)。
図表2 LLMを用いたサービスの開発パターンとセキュリティリスク
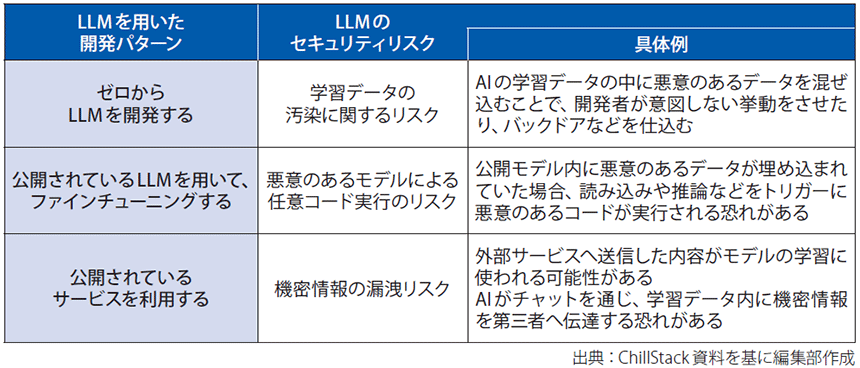
LLMをゼロから開発する場合、開発者が自分たちでデータを集める必要がある。大規模データ収集プロセスにおいては、複数のWebサイトをクローリングするケースが多いが、その際に“データポイズニング”と呼ばれる攻撃に細心の注意を払うべきだというのが伊東氏の指摘だ。ここでいうデータポイズニングとは、AIの学習データの中に悪意のあるデータを混ぜ込み、攻撃者が特定の挙動をさせる“バックドア”を仕込む攻撃を指す。「基本的にLLMの学習用に収集するデータは膨大なので、1つ1つのデータは到底見切れない」と伊東氏は話す。
こういった攻撃からAIを守るには、クローリング対象を健全なWebサイトに絞り込むなど、信頼できる場所から目的に必要なデータを収集することが好ましいという。「研究段階なうえ、悪意のあるデータを100%検知することは難しいが、学習データに潜む明らかにおかしいデータを統計的に発見して取り除いたり、学習方法を工夫することによって悪意のあるデータが少量混ざっていても無力化できる手法も出てきているので、それらを試してみるのも1つだ」と伊東氏。
情報漏洩のリスクもある。特に公開済のLLMを用いたサービスを利用する際に気を付ける必要があるという。AIがチャットサービスを通じて、学習データ内の機密情報を第三者へ伝達してしまう可能性もあるとのことだ。
情報漏洩を防ぐためには、「外部サービスの利用規約の確認に加え、外部に漏れてはいけないデータは送信しないことを徹底すべきだ」と伊東氏。また、OpenAI社などが“自社特化AI”をすでに提供しているが、そういった情報漏洩リスクが低い生成AIの活用も視野に入れる必要があるという。
“産学官”の連携も重要
「自分たちが開発したAIサービスをきちんと設計し、どこにリスクが孕んでいるのか理解しておくことが大切だ。工数が割けないのであれば、外部のセキュリティ会社と連携して対策を進めていくべきだ」と、伊東氏は強調する。例えば、ChillStackは、LLMを用いたサービス開発時のセキュリティコンサルティングサービスを提供。具体的には、各企業のLLM活用シナリオに沿ったセキュリティリスクの洗い出しと対応策の検討を支援する。AIに関する脆弱性診断サービスも展開している。
さらに伊東氏は、“産学官”での連携の重要性も説く。「AIセキュリティはまだまだ研究段階のものが多いので、大学の研究室や研究機関との協業が大事になってくる。また、産業技術総合研究所による機械学習に関するガイドラインが整備されたのも大きい。この啓蒙活動がさらに進めば、セキュリティ意識も浸透していくだろう」(伊東氏)