基盤モデルの「構築」と「使用」に課題
基盤モデルの構築には、(1)膨大なトレーニングデータと、(2)トレーニングと推論に使うための大規模な計算リソースが必要になる。また、(3)並列コンピューティングに関する深い専門知識と、(4)大規模インフラ上に構築する複雑なアルゴリズムの知識も求められる。この4つをどのように用意するかという課題をまずクリアしなければならない。
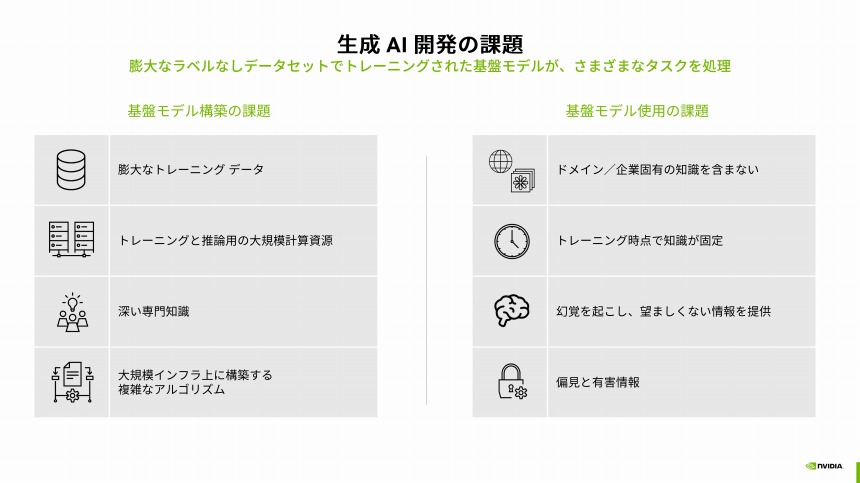
生成AI開発の課題
さらに、基盤モデルを使用する際にも4つの課題があるという(上図表の右側)。
ドメイン/企業固有の知識を持たないことは先に述べたが、そのほかに、トレーニングした時点で知識が固定されるため、時間が経つほどに実世界とのギャップが広がること、幻覚と呼ばれる現象によって事実と異なる情報を提供したり、適切でないトレーニングデータによって有害な情報を提供する可能性があることだ。
エヌビディアは、こうした課題を克服し、生成AI開発と展開を可能にするための各種ソリューションを提供しているという。ハードウェアとソフトウェアの両面で生成AIの開発と活用を支援。それらソリューションはクラウドサービスとして利用することも可能だ。
生成AI向けインフラをクラウドサービスとして提供
生成AIのトレーニングに求められる高い演算能力を提供するのが、同社のGPUだ。澤井氏によれば、ChatGPTは1万基のNVIDIA GPUを用いて数週間のトレーニングを行ったという。
そのトレーニング向けに最適化された最新のGPUが「NVIDIA H100 Tensoeコア GPU」(以下、H100)であり、前世代の「A100」に比べてサーバー数を5分の1にできるという。日本国内でも筑波大学や東京工業大学、さくらインターネット、サイバーエージェント等がH100を導入している。
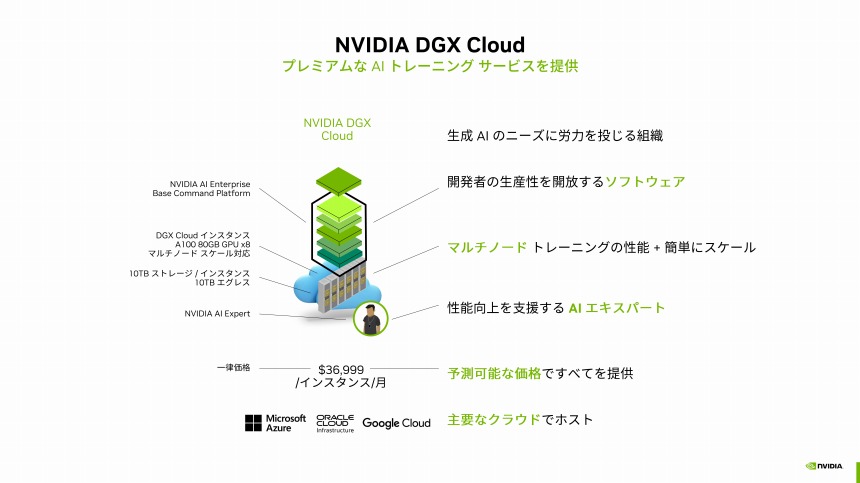
NVIDIA DGX Cloudの概要
また、NVIDIA GPUを使ったAIトレーニングをクラウドサービスとして利用できる「NVIDIA DGX Cloud」も用意されており、Microsoft Azureなどの「主要なクラウド事業者でインスタンスが使える」(澤井氏)。
一方、推論のためのハードウェアも充実させている。画像生成AIの推論に最適化した「NVIDIA L40」や、ビデオ向けの「NVIDIA L4」などをラインナップ。LLM向けには、A100に比べて12倍高速な推論が可能な「NVIDIA H100 NVL」を提供している。

LLMのリアルタイム推論に最適化したH100 NVL
ソフトウェアに関しては、4000以上のソフトウェアをパッケージ化した「NVIDIA AI Enterprise」を提供している。そのうち、生成AIのトレーニングや基盤モデルのカスタマイズ、さらに、生成AIの展開時に安全性やセキュリティ対策を実行するための幅広い機能を提供するのが「NeMoフレームワーク」だ。下図表の通り、基盤モデルの開発から、生成AIを活用したアプリケーション展開までエンドツーエンドにサポートする。
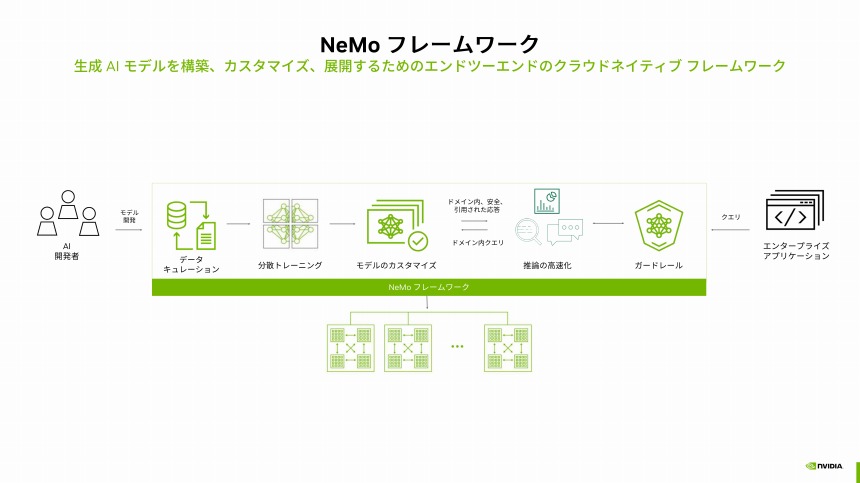
基盤モデル構築から生成AI展開までサポートするNeMoフレームワーク
エヌビディアはこのNeMoについても、クラウドサービス「NVIDIA AI Foudation」として利用可能にする計画だ。前述のNVIDIA DGX Cloud上で提供され、ユーザー企業は「インフラ管理等の心配なく使える」(澤井氏)。
LLM構築向けのサービスとして提供される「NVIDIA NeMoサービス」は、利用する企業が自社専用の生成AIを開発するためのもので、「事前トレーニング済みの大規模言語モデルも提供する」。パラメーター数が80億で応答性に優れた「GPT-8」、パラメーター数が430億で精度とレイテンシーのバランスが取れた「GPT-43」、パラメータ数が5300億で複雑なタスクに適した「GPT-530」の3種類のモデルを用意する。
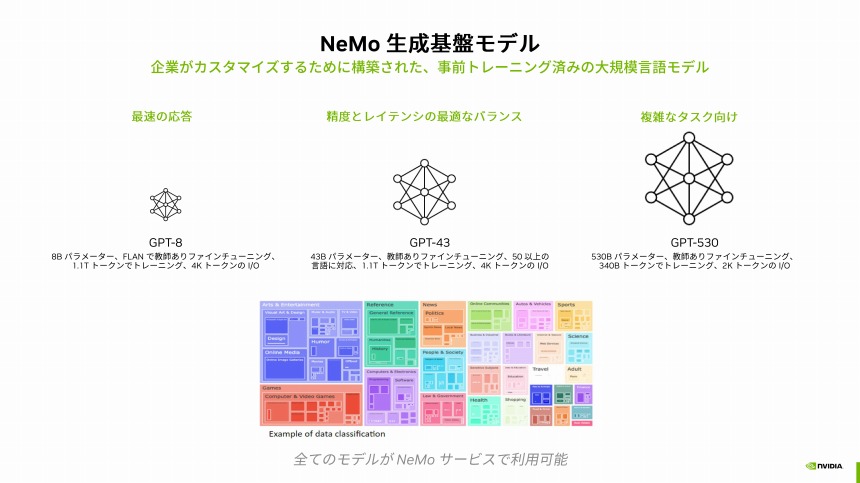
NeMoサービスで提供する3種の基盤モデル
このほか、画像・ビデオ生成AI向けの「NVIDIA Picasso」、創薬業向けに特化した「NVIDIA BioNeMo」も用意し、幅広い業界のニーズに応える。
こうした取り組みにより、現時点で1600以上の企業が生成AIの開発と活用にNVIDIAのソリューションを活用しているという。