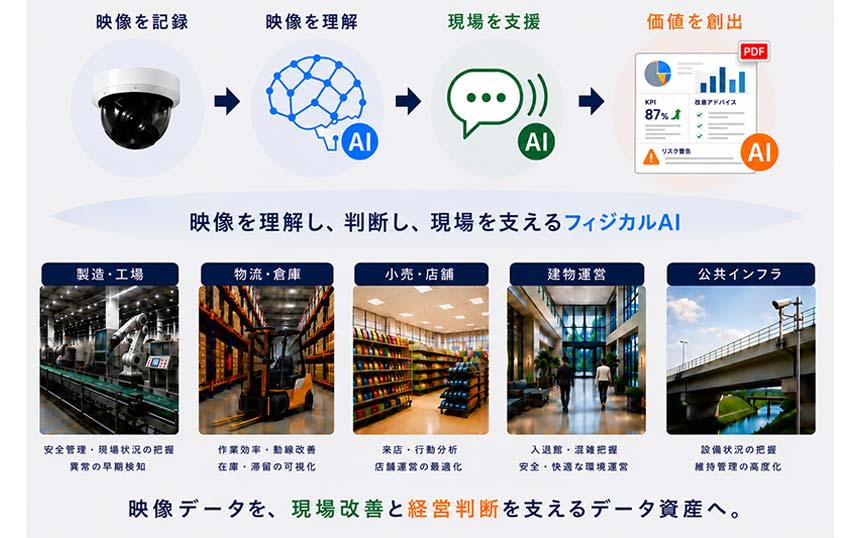
大規模言語モデル(LLM)のトレーニングをはじめとするAI学習は現在のところ、データもコンピューティングリソースも大規模データセンター(DC)に集約して行う「中央型」が主流だ。だが、AIの発展の方向性は徐々に「分散型」へと変化し始めている。
これには主に2つの理由がある。
1つは、生成AIが直面する環境負荷の問題を解決するためだ。
AIの巨大化によって消費電力量は増加の一途を辿っている。これまで1カ所のDCで行っていたAI処理を複数のDCに分散し連携させることができれば、電力消費も分散化できる。局所的に余剰電力が生じやすい再生可能エネルギーを効率的に活用できる可能性もある。
AIアプリは「分散推論」へ
もう1つ、「中央」のクラウドから、データの生成場所に近い「エッジ」へとAI処理を移動・分散させることで得られるメリットもある。データの機密性を高められることと、AI処理の低遅延化だ。データを一箇所に集めず、分散した環境で機械学習モデルのトレーニングを行う「連合学習」、クラウドだけでなくデバイス内やネットワーク内のMEC(マルチアクセスエッジコンピューティング)でもAI推論を行う「分散推論」といった考え方は、この効果を狙ったものだ。
連合学習(Federated Learning)は、分散されたデバイスやサーバーで学習した結果のみを中央に集めるので、プライバシー保護やセキュリティの強化につながる。大量のデータを送信する必要がないので、通信コストも抑制できる。
分散推論も同様に、プライバシー保護やセキュリティ強化、通信コスト低減に貢献する。さらに、データの発生場所に近いエッジからデバイスへ推論結果を戻すことで伝送遅延を短縮できる。機械/ロボット制御や自動運転など、リアルタイム性が求められる場面にAI推論を適用できるようになる。
AIエージェントを活用したアプリケーションの開発と普及が進むに連れ、ユースケースの拡大をもたらす分散推論が大きなトレンドとなることは間違いない。当然、デバイスとエッジAI、クラウドをつなぎ合わせるネットワークと、その運用者である通信事業者の役割も増大する。