東京大学 教授/東京大学 インクルーシブ工学連携研究機構 機構長 川原圭博氏
――ChatGPTの登場は、世の中に大きな衝撃を与えました。生成AIは今後さらにどう進化していくとお考えですか。
川原 人々がChatGPTに驚いているのは、あたかも人間が考えているかのように、文章を流暢に生成できるからです。こうしたことが可能になったポイントの1つとしては、「テキストだから」ということが挙げられます。人間が今まで書き溜めてきた書籍やWeb上などのテキスト情報をふんだんに取り込んで、抽象化した概念を取り出し、その概念をまた具体化させて、文脈に応じた文章を生成するといったことが可能になりました。
では、次はどこへ向かうのでしょうか。いろいろな予測がある中、私は国の仕事の一部として約50人の専門家にインタビューし、未来シナリオを整理しました(図表)。
図表 AIの望ましい未来シナリオとリスク
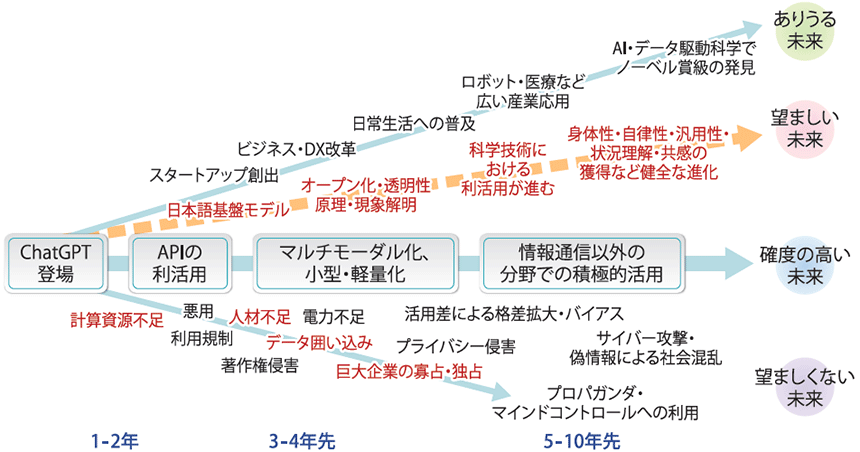
テキスト生成AIの地続きとして、今後は画像や音声なども取り扱えるようになるマルチモーダル化が進展していくでしょう。さらに生成AIがロボットに組み込まれれば、身体性を獲得し、基盤モデル自身で動き方を修得したり、作業を自動化したりといったことが起こってくると考えています。
今の生成AIは“頭でっかち”
――学習データを与えられるだけではなく、生成AI自身でも自ら経験しながら学習していくのですね。
川原 ChatGPTのような大規模言語モデル(LLM)は、知識重視のAIと言えますが、世の中には当たり前すぎて、言語化されていないことも数多くあります。生成AI自身が身体性を獲得し、実際に自分のカラダを動かして得た経験も入ってくると、今の“頭でっかち”な生成AIとは全然違うものができてくると思います。
グーグルのロボットチームは、飲み物をこぼしてしまったときなどに、ロボットがどう行動すべきかをロボット自身に判断させるのにLLMを応用していました。従来もロボットを自律的に動作させることは、あるパターンに備えて事前にプログラミングしておけば可能でしたが、雑巾を持ってくるシチュエーションだけでも数多くあります。基盤モデルが人間の行動のある種の常識を学び、ロボットに自動で推薦するというのは、まず最初に来る未来だと思います。
ヒューマノイド(人型ロボット)を作る場合を考えても、関節の自由度が大きすぎて、今までは「指の角度は何度か」といったことまで事前に細かくプログラミングする必要がありました。しかし人間の場合、スポーツやダンスにしても、他の人のやり方を見たり、あるいは言葉によるアドバイスを聞いて、コツを掴んで自分のカラダの動きに反映させることができます。今の機械学習はトレーニングを無数に繰り返さなければならないので、先にロボットが機械的に故障してしまうのですが、そうした課題を乗り越えられれば、生成AIでロボットが動きを自分で学ぶことが可能になっていくと思います。
――人間の能力にますます近付き、人間の能力を超えるシンギュラリティ(技術的特異点)もそう遠い未来ではなさそうです。
川原 AI研究者がChatGPTについて一番驚いたのは、膨大なデータとGPUリソースを使って、何カ月もかけて基盤モデルを作ると、信じられない性能が導き出されるということでした。
LLMがやっていることは、テキストの続きを予測することであり、実はシンプルです。「英国の首都は」と言ったら「ロンドン」というように、人間は抽象化された状態で頭の中に眠っている、過去に見聞きしたことを呼び起こしながら次の言葉を探しますが、同じようなことがコンピューターの中で起こっています。大量のデータを処理して記号化し、その記号の続きがどのような抽象度の高い意味を持つのか、といった情報処理を実行しているのです。
そして、こうした情報処理によって実現できることは、質問に対する受け答えや翻訳などだけに限りません。例えばタンパク質の構造予測やゲノム解析などでも、すでに素晴らしい成果が出始めています。
5~10年先を見据えると、AIやデータ駆動科学によって、ノーベル賞級の発見がなされることも、ありうる未来でしょう。