イーサネットを選んだ理由と苦労
この3要件を満たすための選択肢は2つある。RDMA専用に設計されたInfiniBandを使うか、イーサネットでRDMAを実現するRoCEv2(RDMA over Converged Ethernet version2)を採用するかだ。LINEヤフー/Acpatioは後者を選択。イーサネットのオープン性が「非常に大きなポイントだった」(大浦氏)。
また、Actapioの立見祐介氏は、「イーサネットを長年使ってきた資産」も選択の理由に挙げる。「ノウハウもツール類も山ほどある。それを活かす意味でもオープンなイーサネットを選んだ」
ただし、慣れ親しんだイーサネットといえど、従来のClos Networkとの違いで苦労した点は少なくない。「GPU間通信専用のトポロジーによって設計することや、RoCEv2特有の輻輳制御の仕組み、そして、サーバーに挿すNIC(ネットワークカード)とのパラメーター連携といったものが重要になる」と大浦氏。
Actapioの北野拓也氏は、製品選定、検証の苦労を振り返る。「新たな機能要件が入ってくるなかで、価格も考慮しながら機種を選定しなければならない。スイッチもトランシーバーも様々なベンダー/規格がある。リンクができて、実際にトラフィックが流れて、期待通りの速度が出るのか、GPU間通信に必要な要件を満たしているのか。まったく新しい領域、構成ならではの大変さがあった」
最初のGPU専用ネットワークは2022年から検討を開始。当時は稼働実績がある製品は限られていたことから、NVIDIAの400GbE対応スイッチ「Spectrum SN4700」を導入した。サーバーNICにも、NVIDIAConnectX-7 NICを使用している。
Rail-Optimized構成を採用
Acpatioの米国DCで現在稼働中の400GbE GPUクラスターは、図表1のような構成となっている。ネットワークトポロジーは、NVIDIAのリファレンスアーキテクチャにも採用されているRail-Optimized構成を選択。RailとはGPUサーバー間通信の最短経路のことだ。
図表1 GPUネットワークの構成
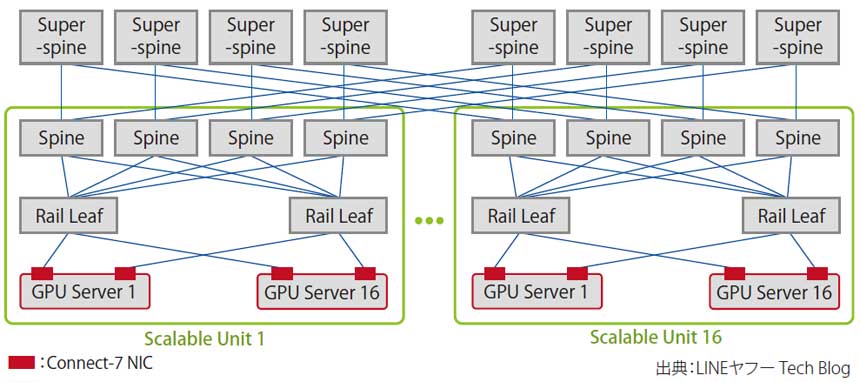
GPUサーバー間が最短経路で通信することに最適化されたこのトポロジーでは、GPU間のデータ転送はLeafスイッチの折り返しで完結する(図中のRail Leaf)。このRail間をつなぐためにClos Networkを構成することで、高いパフォーマンスとスケーラビリティの向上を狙っている。
GPUサーバーを16台、HGX H100GPUを128基で1つのScalable Unit(SU)を構成(図中の緑枠)。これを、Super-Spineスイッチで相互接続する。SUを増やすことで、最大2048基のGPUを収容可能という。
「ロスレス」を実現するうえで欠かせない輻輳制御については、ネットワークの輻輳をエンドノードに伝えることで制御するECN(Explicit Congestion Notification)と、アプリ単位でフローを制御して輻輳を抑制するPFC(Priority Flow Control)を組み合わせたDCQCN(データセンター量子化輻輳通知)を使用して実現している。