<連載>実践 生成AIの教科書の第2回では、各企業での典型的な取り組みをご紹介します。多くの場合、取り組みは以下の順に進めます。
(1) 社内の推進体制を確立する
(2) セキュアな社内利用環境を整備する
(3) 利用ガイドラインを作成する
(4) 各種業務への適用を開始する
(5) 社内データを活用する
各ステップでどのようなことを行うか、順に見ていきましょう。
(1)社内の推進体制を確立する
まずは生成AI活用のための推進体制を築く必要があります。一般的には以下のいずれかの部門が中心となり、社内から関係者を集めて組成するケースが多くあります。
・経営企画部
・DX(デジタルトランスフォーメーション)推進部
・情報システム部
全社の中で生成AIをどう適用し、どう効果を上げていくのか、計画を立てていく必要があり、通常は経営企画部またはDX推進部がリードして進めていきます。また、社内の利用環境を整備する必要があるため、情報システム部門の参画が必須になります。
(2)セキュアな社内利用環境を整備する
一般に公開されているOpenAI社のChatGPTでは、先述のとおり、入力データがAIの学習に利用されるなどの可能性があります。一方で「社内情報を入力データとして活用したい」というニーズは当然あり、その場合は、よりセキュアな利用環境が求められます。一般的には以下のようなクラウドベンダによるパブリッククラウドサービスを選択するケースが多いです。
・Microsoft Azure OpenAI Service
・Amazon Bedrock
(3)利用ガイドラインを作成する
生成AI活用のリスクを低減するために、セキュアな社内利用環境とともに、「生成AIをどこまで使ってよいか」を明確にするための利用ガイドラインも整備・提供します。一般的には以下のガイドラインや文書を参考にして作るケースが多いです。
・一般社団法人日本ディープラーニング協会「生成AIの利用ガイドライン」
・「東京大学の学生の皆さんへ:AIツールの授業における利用について」(ver. 1.0)
また、すでに「パブリッククラウド利用ガイドライン」や「責任のあるAI(Responsible AI)」に向けた原則などを定めている企業も多くあります。その場合は既存のガイドラインを活用しつつ、その上で生成AIに特化した部分のルールを明確化することになります。例えば、生成AIが出力した文章や画像を活用する場合、「生成AIを利用したコンテンツ」であることを明示するなどです。
(4)各種業務への適用を開始する
生成AIは企業の中で様々な業務で活用できます。よくある例を表1.1に示します。より具体的な内容については、単行本版の『実践 生成AIの教科書 ――実績豊富な活用事例とノウハウで学ぶ』の4章から8章で説明しています。
表1.1 各種業務への適用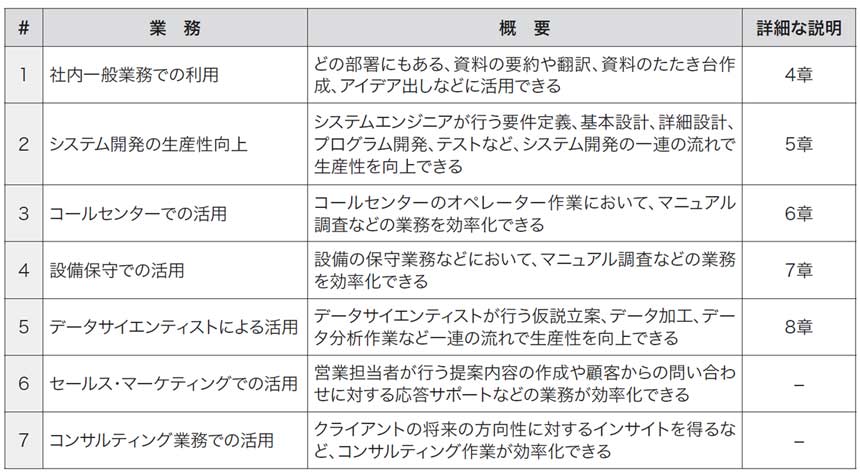
(5)社内データを活用する
「生成AIに自社内のデータを学習させたい」というニーズはどの企業にもあります。やり方は大きく3つあります。LLM(大規模言語モデル)を①ゼロから構築するパターン、②ファインチューニングするパターン、③RAG(Retrieval Augmented Generation)を用いるパターン
の3つです(図1.6)。

図1.6 社内データの学習
3つの中で、③RAGを採用する場合が一般的です。RAGでは既存のLLMをそのまま流用します。学習させたい社内データを、知識DB(Database)またはベクトルDBと呼ばれる専用のデータベースに蓄積し、質問に応じて必要な情報を知識DBから検索・抽出し、LLMに参考情報として渡します。そうすることで、生成AIの出力に社内データを反映させることができます。
RAGの処理方式では、ユーザーが発した自然言語での質問文に応じて、知識DBを検索して質問文に類似する文書を抽出し、質問文と類似の文書をセットにして生成AIに問い合わせます。これによって、社内データを組合せた結果を得ることができます(図1.7)。
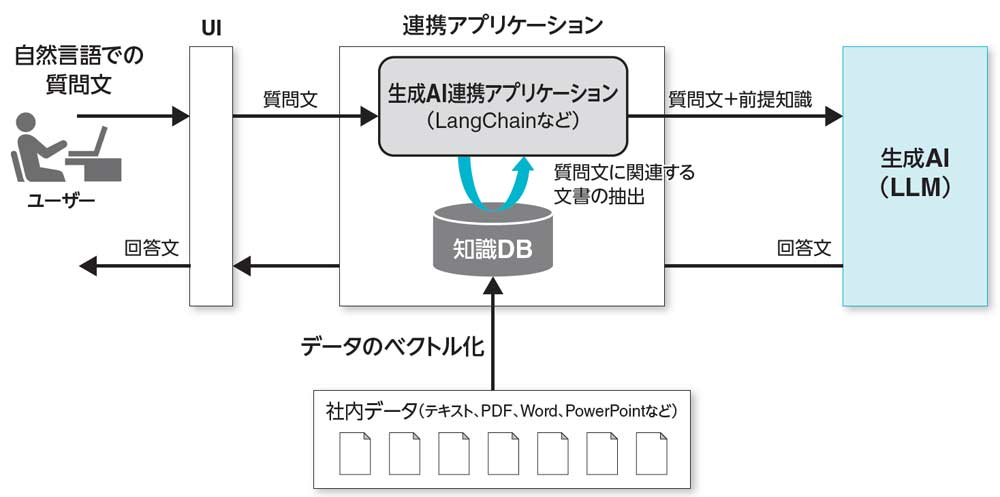
図1.7 RAGを用いた処理方式
この処理方式を実現するためには、生成AIの手前に連携アプリケーションを構築する必要があり、多くの場合、生成AI向け開発フレームワークLangChain(オープンソース)などが使われます。また、「社内データはなるべく社内システムで管理したい」というニーズも多く、その場合、連携アプリケーションはオンプレミスのシステムとして構築し、生成AI部分のみにMicrosoft Azure OpenAI Serviceなどのパブリッククラウドサービスを活用します。
なお、RAGで障壁となりやすいのは、社内データを知識DBへ蓄積するための適切なデータ加工処理です。社内データにはテキストだけでなく図表や画像データが多く含まれており、これらを生成AIで読み込める形式に整形した上で、適切な検索結果が返ってくるかを検証する必要があります。RAGについて詳しくは、単行本版『実践 生成AIの教科書 ――実績豊富な活用事例とノウハウで学ぶ』の6章「コールセンターでの活用」の中で説明しています。