既存のイーサネット市場とは、違う力学が働いている──。
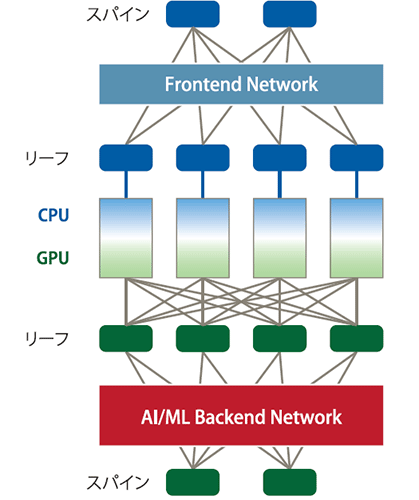
AI開発の基盤であるGPUクラスターのインターコネクトは、従来のデータセンター(DC)ネットワークとは要件と構築法が根本的に異なるため、「AI/ML Backend Network」(図表1)と呼ばれる。そこで使われる技術の進化は、既存のネットワーク市場とは比較にならないほど早い。
図表1 AI/MLネットワークの構成
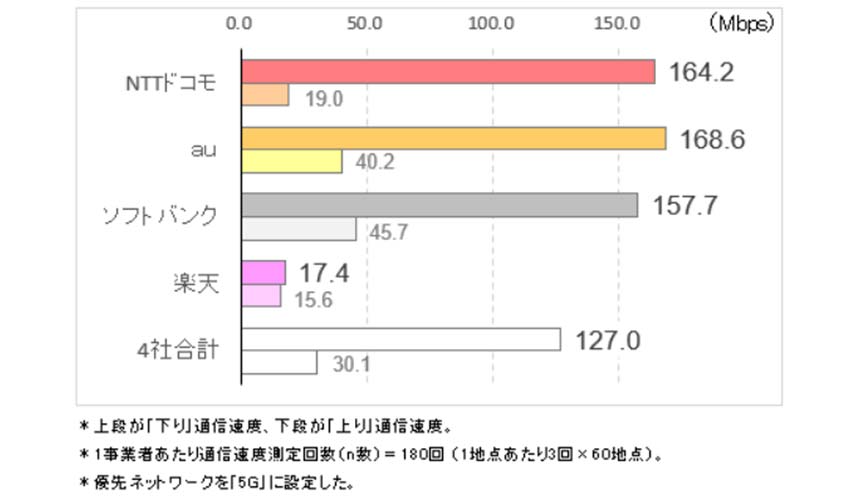
背景にあるのは、広帯域化への強烈なニーズだ。アリスタネットワークスジャパン 副社長の兵頭弘一氏によれば、現時点で最も広帯域な800ギガビットイーサネット(GbE)を「今すぐテストしたいと言うのは、ほぼAI開発のお客様」。他の市場セグメントでは400GbEがようやく導入され始めたところだが、AI/ML Backend Networkでは、まだ製品化されていない1.6TbEも「レディになれば、すぐにも使われるだろう」。

アリスタネットワークスジャパン 副社長 兼 技術本部長 兵頭弘一氏
800Gも1.6Tも「すぐに使い切る」
イーサネット市場は、ハイパースケーラーへの主役交代とともに変容した。従来なら、一度構築したネットワークは5~6年使うのが常識。だが、DC/クラウド事業者はライバルに対する優位性が得られるなら、新技術の採用を躊躇わない。
AI/ML Backend Networkは、それが最も顕著な領域だ。
GPUの進化は目覚ましく、GPU間インターコネクトも合わせて進歩しなければ、性能をフルに発揮できない。「高価なGPUを活かすためなら、減価償却が終わっていなくてもネットワークを変えることを厭わない。GPUをいかに使い倒すかという観点だけで決まる」(兵頭氏)のがこの市場だ。以前ならネットワーク帯域は常に潤沢にあり、コンピューターの高速化を待っている状況だったが、今ではすっかり逆転。「800Gでも1.6Tでも、帯域を渡したらその日に全部使い切る。業界の構図が変わった」
通信ネットワーク市場の調査を行うDell’Oroによれば、AI/ML Backend Networkの更新サイクルは18~24カ月。2025年には出荷ポートの約6割が800GbEに、2028年には約7割が1.6TbEになると予測している。