富士通は2024年12月12日、製造・物流現場の作業効率化や安全性向上を支援する「映像解析型AIエージェント」を開発したと発表した。
この映像解析型AIエージェントには、ドキュメント情報をもとに現場理解能力の拡張を行う「自己学習技術」と、映像を効率的に解析する「コンテキスト記憶技術」が搭載されている。
自己学習技術は、マルチモーダルLLMが映像から認識できない事象について、ドキュメントの言語情報を対応付けて学習し、AIエージェントの映像理解能力を拡張することができる。
具体的には、ドキュメントに含まれる対象物を選択し、機械学習により対象物との距離を推定して3次元データを仮想空間上に作成。ドキュメントから作成した質問と、3次元データからわかる回答を作成し、それらを学習データとしてマルチモーダルLLMをファインチューニングする。同技術を用いて人と物体の距離を3次元で推定することで、物流や建設の現場における安全管理や、製造現場における作業状況の生産管理システムへの自動入力などを実現できるという。
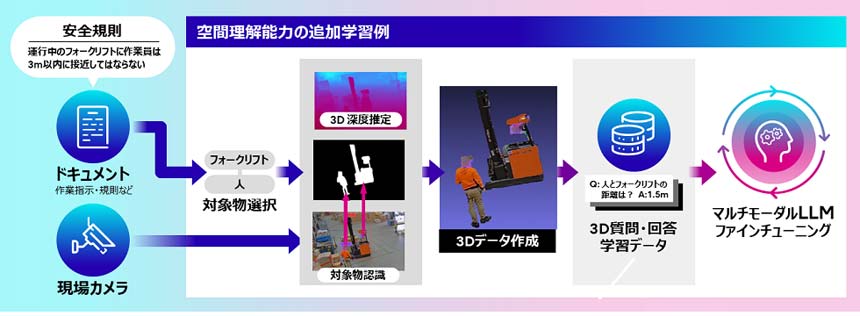
現場理解能力の追加学習の例
マルチモーダルLLMでは、サイズの大きい長時間の映像を入力する際にフレームを間引くため、時系列で変化のある映像を分析する際に回答の精度が落ちるという問題があった。コンテキスト記憶技術では、重要な情報に注意を集中することで効率的に視覚情報を処理する、人間の「選択的注意」というメカニズムに着目している。
対象映像の中でAIエージェントのタスクで検知したい「人の安全行動」などの主題をプロンプトとして与えると、「選択的注意」により、主題に適合するフレーム内の特徴量のみを選択し、圧縮して映像コンテキストメモリとしてビデオメモリに格納する。映像コンテキストメモリを用いることで、フレームを間引くことなく長時間映像をマルチモーダルLLMが扱えるようになるという。
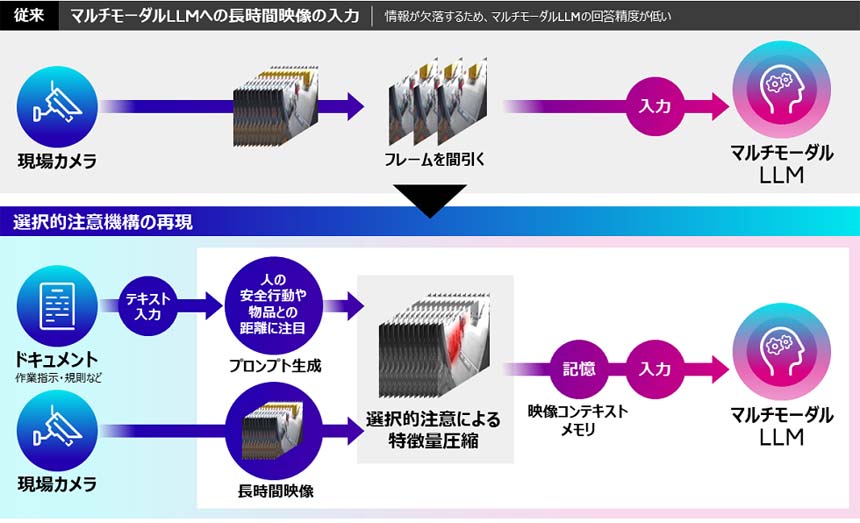
選択的注意機構を用いた映像のコンテキスト記憶
また、映像解析型AIエージェントのための評価環境「FieldWorkArena」を開発。実際の工場や倉庫の画像・映像、規則や手順書などのドキュメント、模擬の業務システム、AIエージェントが解決すべきタスク群が含まれ、AIエージェントの実業務での性能を評価することができるとしている。