「AIによって、リアルな音声付き動画をAIによって作り出す動画合成技術」――。
シンセティック・メディアを一言で説明するとこうなる。人の顔・声のデータとテキストを用意するだけで、AIが“その人が本当に話しているような”動画を生成してくれるというものだ。
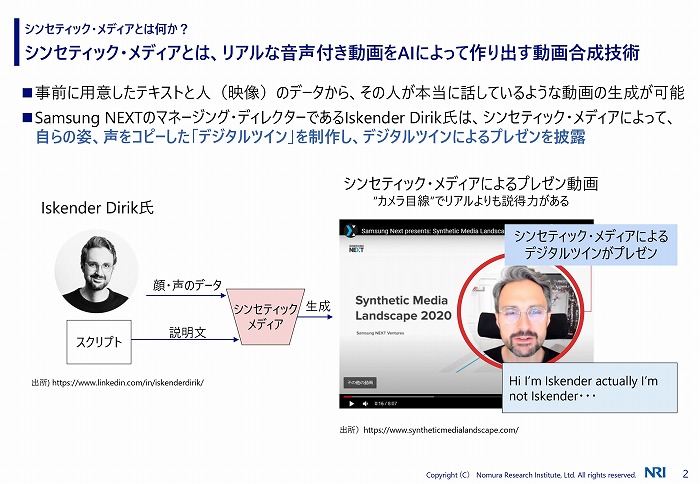
人の姿・声をコピーした「デジタルツイン」を容易に生成できる
長谷氏が例に挙げたのが、2019年に話題となった「フェイク・ザッカーバーグ」だ。Facebook 共同創業者兼会長兼CEOのマーク・ザッカーバーグ氏のフェイク動画であり、長谷氏によれば、わずか「24時間の学習でAIが作成したもの」という。
“フェイク”ではないが、2013年に米Digital Domeinが制作した「ヴァーチャル・テレサ・テン」は人間が手作業で制作したフルCG動画で、これには多数のクリエーターが約16億円の費用と5カ月の期間をかけた。わずか6年で技術は飛躍的に進歩したわけだ。

野村総合研究所 上席研究員の長谷佳明氏
このシンセティックメディアのキーとなる技術は、Neural Rendering(ニューラルレンダリング)である。AIがCGモデルを制御し、リアリティの高い画像を作り出す技術だ。非常に細かな制御を行うことで、写実性が高く、音声に合わせた口元を忠実に再現できる。新型コロナウイルス対策として教育や接客の場での動画活用ニーズが急拡大しており、「生産性の高い動画制作技術が求められている」ことからシンセティック・メディアへの注目が高まっていると長谷氏は指摘した。

英Synthesia社のシンセティック・メディア自動生成サービス
これを牽引するベンダーの1つが、英Synthesia社だ。任意のテキストを読み上げる人物動画を自動生成する技術を開発。商品説明などの接客用途を想定しており、「日本語を含む40カ国語をサポートしている」(長谷氏)。好みのキャラクターを選び、テキストを入力するだけでわずか数分で合成動画が生成される。