AIデータセンター(DC)でGPUクラスターを構成するための“AIバックエンドネットワーク”を構築するに当たって、InfiniBandよりも使い慣れたイーサネットが選択されるケースが増えてきている。
HPC/AI向けに特化したInfiniBandは、高い信頼性とロスレス通信を実現するために設計された規格であり、汎用性とコスト効率を追求するイーサネットとは、成り立ちも進化の方向性も異なる。InfiniBandへの支持はまだ根強いものの、イーサネットの性能向上によって競争が激化している。
イーサネットには、ベンダー非依存のオープン性や安価なコスト、既存インフラとの互換性といった利点がある。運用担当者にとっては、これまで培ったノウハウや運用管理ツール等の資産を活かせる点も魅力だ。
イーサネットで、InfiniBandに匹敵する性能と高信頼性が実現できれば、まさに理想的。これを実現する肝となるのが“ロスレス”だ。パケットロスはAI学習処理の効率を、つまり超高価なGPUの利用効率を大きく毀損してしまう。パケットロスが発生することを前提に設計されたイーサネットをAI-DC対応にするための技術/ソリューション開発が進んでいる。
NW性能がGPU利用効率を左右
「AIタスクの失敗の約20%がネットワーク問題に起因しているという調査もある。GPUの性能を引き出すには、安定したロスレス通信が不可欠だ」と語るのは、日本ヒューレット・パッカード HPE Networking事業統括本部 技術本部 テクノロジーコンサルティング部 部長の塚本広海氏だ。
AI学習・推論処理では、複数のGPUがデータ交換・同期を繰り返して分散処理する集合通信が行われる。その際は効率的かつ低遅延に高速伝送を行うために、CPU/システムメモリを介さず、GPUメモリー同士で直接通信する(図表1・2)。
図表1 GPUのサーバーアーキテクチャ
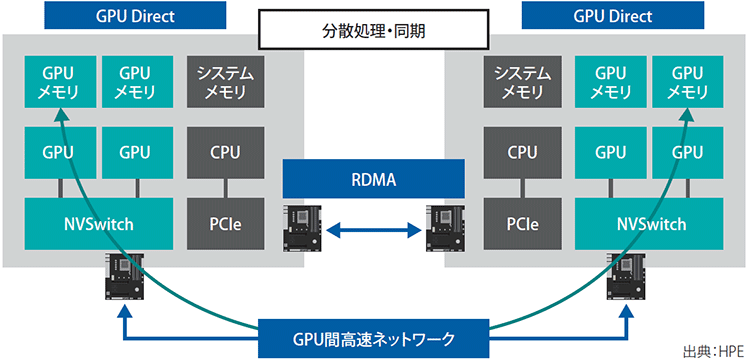
図表2 GPU分散高速通信の特徴
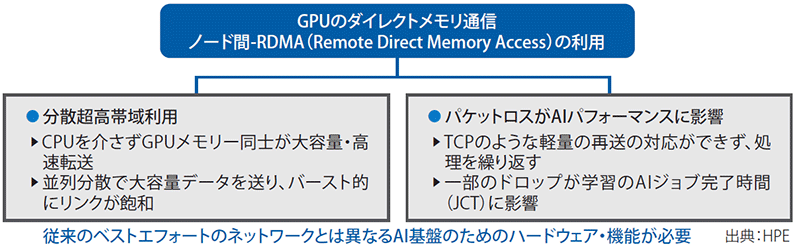
ここで使われるのが、RDMA(Remote Direct Memory Access)だ。InfiniBandはそのための専用規格であり、GPU間通信をイーサネットで構築する場合は、RDMAをイーサネット上で実行するRoCE(RDMA over Converged Ethernet)を用いる。IPベースでルーティングできるRoCEv2が主に使われている。
このRDMA/RoCEは「パケットロスやパフォーマンスの劣化に敏感」(同氏)だ。TCPのような軽量の再送処理ができないため、ロスが起こると処理をやり直す。
「わずかでもロスや遅延が発生し、1つのサーバーの処理が遅れると、全GPUに待ち時間が生じてしまう」と話すのは、計測器・テストソリューションを提供するVIAVIソリューションズ HSE&Security ジャパンカントリー マネージャーの中村彰宏氏。「DC構築コストの全体から見れば、ネットワークの投資額はわずかなもの。しかし、その品質が悪いと、巨額を投じたGPUサーバーをフル稼働できなくなる」。そのため、需要に応じて段階的に増強するキャリアネットワークと異なり、AI-DCでは最初から最高速・高品質なネットワークを整備することでGPUの稼働率を最大化し、早期の収益化を目指す戦略が採られる。