データセンターから企業の拠点や家庭まで、エンドツーエンドに光だけで通信するIOWN APN(オールフォトニクス・ネットワーク)。その有望なユースケースの1つと考えられているのが、データセンターの分散化だ。
これは、高速大容量かつ低遅延なAPNで遠隔地のデータセンターを接続して、1つの巨大なコンピューティングリソースとして利用しようとするコンセプトである。生成AIのトレーニングのように膨大な計算資源を必要とするケースでの需要が見込まれている。

NTTコミュニケーションズ イノベーションセンター IOWN推進室 担当部長の張暁晶(ちょう ぎょうしょう)氏
NTTコミュニケーションズ(NTT Com)が2023年4月に設立した研究開発組織「IOWN推進室」が今回、その実用化への一歩となる実証実験を行い、成功した。IOWN APNで接続した分散データセンターでGPUクラスターを構成。生成AI学習を行って、単一データセンターでの処理と比較するというものだ。
実験環境は小規模なものであり、実用化には多くの課題がまだ残されてはいるものの、単一データセンターでの処理とほぼ互角の性能が確認できたという。イノベーションセンター IOWN推進室 担当部長の張暁晶氏は「小規模な生成AIモデルの事前学習や追加学習など比較的軽量な処理に対しては、単一のデータセンターと遜色ない性能を発揮できると確認した」とその成果を強調した。
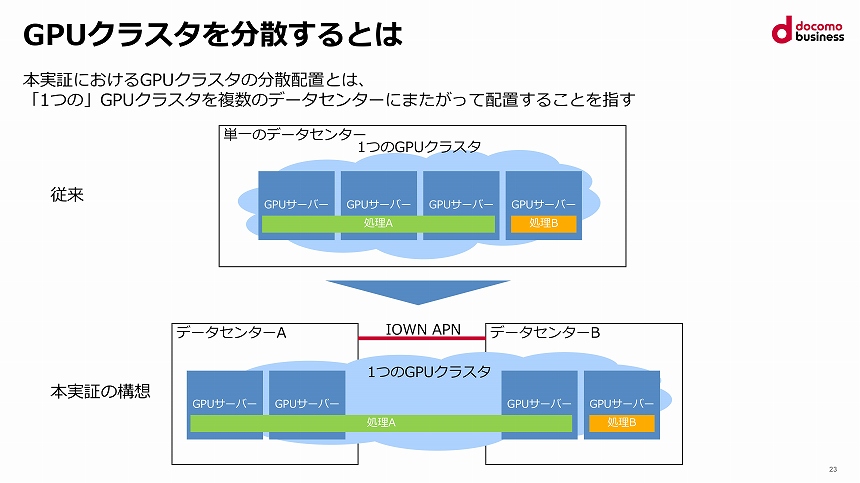
GPUクラスターの分散配置のイメージ
「データセンターの分散化」が必要な3つの理由
張氏によれば、現在のデータセンターには、大規模な計算資源を調達するにあたって制約と課題がある。
生成AIの学習には、多くのGPUを接続して並列分散処理させる「GPUクラスターを利用するのが一般的」(同氏)だ。現時点では単一データセンター内でGPUクラスターを構築しているが、AIモデルが進化・大規模化するに伴って、いくつかの制約が出てきている。
1つが、AIモデルのサイズと処理量が変動するのに合わせて、「GPUリソースをオンデマンドに追加することが難しい」点だ。現在はGPUが品不足の状況で、調達するだけでも数カ月や半年といった長期間を要する。
2つめは、企業が機密度の高いデータを生成AIで取り扱おうとした場合、そのデータを保管するストレージがある拠点の外へデータを移動できないという問題だ。
最後に、学習を行うために必要なコンピューティングリソースを「単一データセンターにすべて押し込もうとすると、ラックスペースや電力供給能力の制限にぶつかる」。
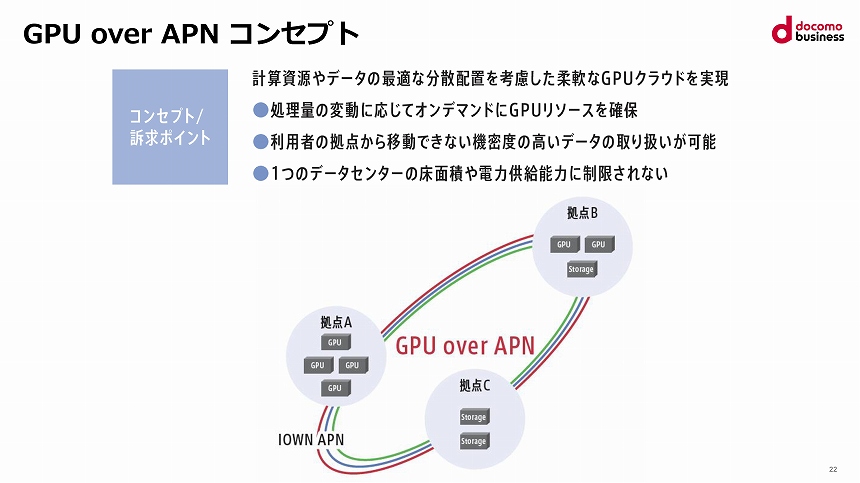
GPU over APNコンセプトのイメージ
NTT Comはこうした課題を解決するため、APNを介して遠隔拠点間でGPUクラスターを構成する「GPU over APN」コンセプトを提唱。今回、東京都・三鷹と秋葉原のデータセンターをAPNで接続し、その実証実験を行った。