2拠点のDCを数百本の光ファイバーケーブルで直結し、800Gbpsの光波長多重伝送で連携させて1つの巨大なGPUクラスターとして機能させる──。
これは、ハイパースケーラーが実際に北米で構築しているAIインフラの例だ。
北米のハイパースケーラーは目下、AI社会の基盤となるGPUクラスターの大規模化競争を続けている。その規模は最早、1拠点には収まりきれないほどに巨大化。より大規模なAI計算資源を確保するには、複数のDCを密接に連携させて1つの計算基盤として機能させる新テクノロジーが不可欠となった。
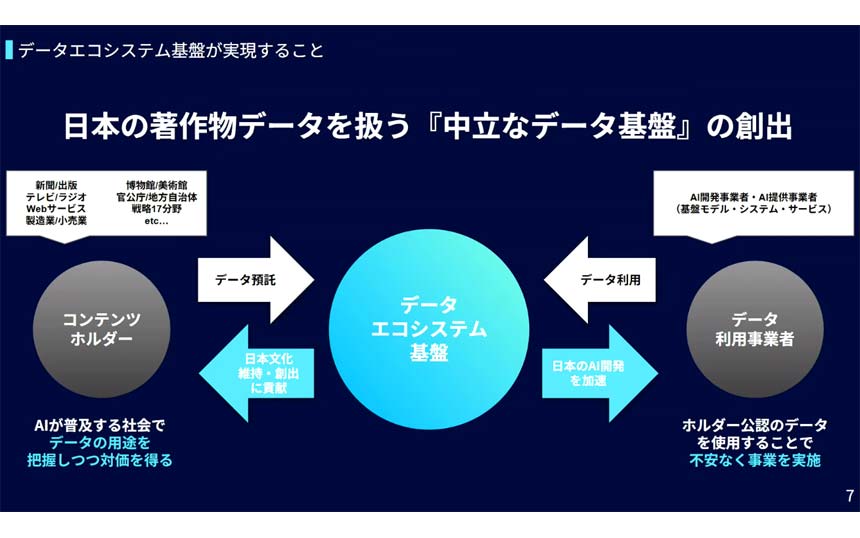
「スケールアクロス」がまさにそれだ(図表1)。データセンター間接続(DCI)のための新しいネットワーク概念である。
図表1 スケールアクロス
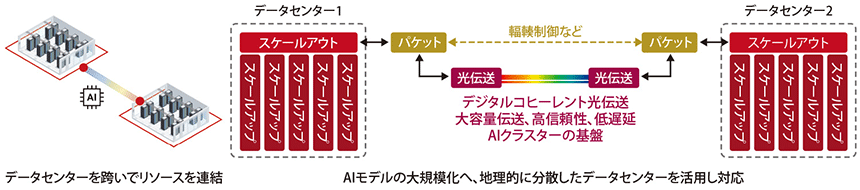
AIモデルの大規模化とAgentic AI時代の基盤へ
上記のプロジェクトに光伝送ソリューションを提供しているのがシエナだ。日本シエナコミュニケーションズ 執行役員 システムエンジニアリング本部 本部長の今井俊宏氏によれば、こうした新たなDCIを「AIのためのWAN」と呼んでいる。求められる要件が、従来のDCIとは大きく異なるためだ。

日本シエナコミュニケーションズ 執行役員 システムエンジニアリング本部 本部長 今井俊宏氏
AIのためのWANは、2つの観点でハイパースケーラーの関心を引き寄せている。AIモデルの大規模化によって直面する課題に対処すること、そして、来たるべきAgentic AI時代に適応するインフラを構築することだ。
AIインフラの最大の課題は、ドメインを超えた拡張性を獲得することだ。単一DCが供給できる電力と収容能力は限界を迎えており、AI計算資源を分散化する必要がある。また、フロンティアAIモデルには、より分散された環境での同期と、膨大なトラフィックを処理するための帯域が求められる。そのためには、DCIの革新が欠かせない。
まず、圧倒的な広帯域化が必要だ。2拠点のAIクラスターを直結するスケールアクロスでは「拠点間の大量のファイバーを同時に、かつ、Day1(稼働開始日)から800Gbpsで全波長を使う」(今井氏)。トラフィック需要の増加に合わせて段階的に帯域を増強してきた従来のDCI構築手法は通用しない。さらに、AIの性能を引き出すには安定したロスレス・低遅延通信が不可欠だ。ロスや遅延で生じる処理待ち時間は、AIインフラ全体の効率を甚だしく毀損する。