ソフトバンクと米国の半導体設計企業である Ampere Computing LLC(以下、Ampere」)は2026年2月17日、次世代のAIインフラを構成する要素の1つとして、CPUを活用したAIモデルの運用の効率化に向けた共同検証を開始したと発表した。
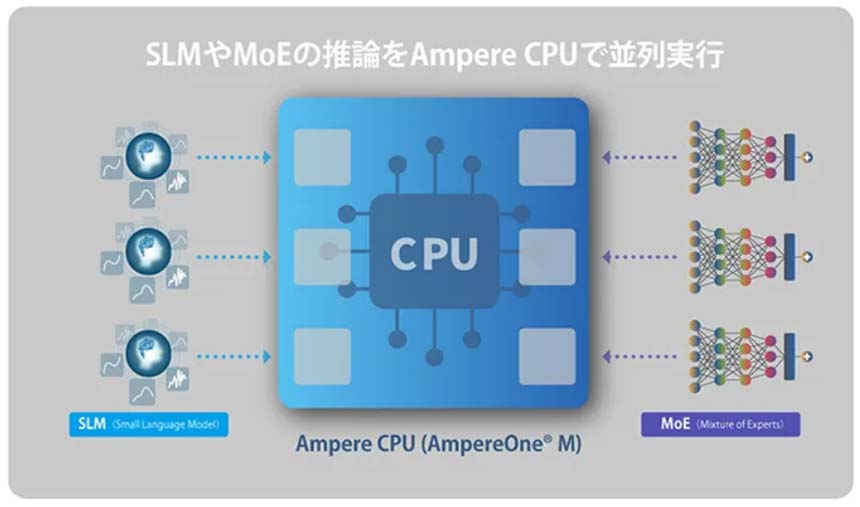
今回の共同検証では、分散型の計算環境を想定し、AIエージェント向けのSLM(Small Language Model:小規模言語モデル)およびMoE(Mixture of Experts、 推論の際に一部の専門家(Expert)のみを動作させることで計算処理の負荷を抑えるモデル)を対象に、CPU上でのAI推論環境における性能やスケーラビリティー、運用性を評価した。
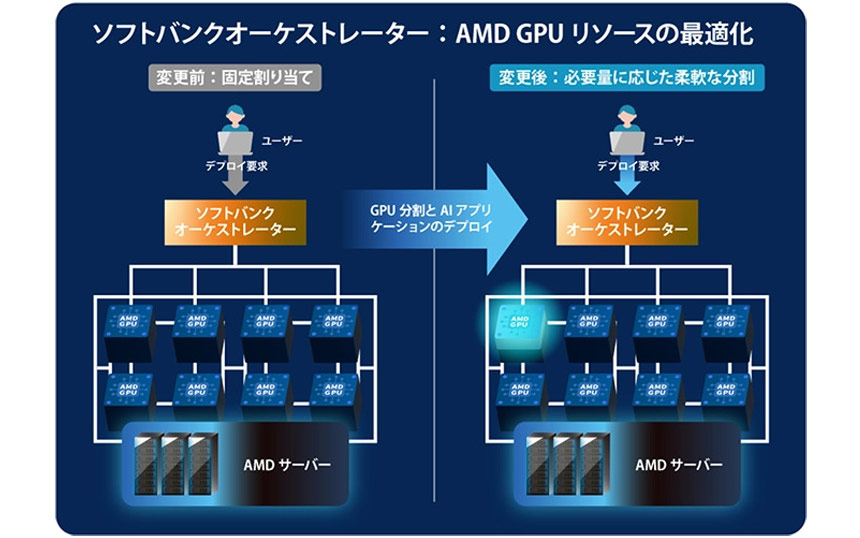
また、CPUのみを搭載したノードや、CPUとGPUを搭載したノードなどのマルチノード環境を前提として、オーケストレーターに最適な配分制御機能を実装することで、ユースケースや計算処理の負荷などの特性に応じてAIモデルを柔軟に配置・管理し、最適化できることを確認した。
さらに、オープンソースのAI推論フレームワーク「llama.cpp」をベースに、Ampere製のCPU向けに最適化した「Ampere optimized llama.cpp」を実装することで、一般的なGPUベースの構成と比較して、消費電力を抑えながら同時実行可能数を増加できることを確認。加えて、AIモデルの読み込み時間が大幅に短縮され、モデルの高速な切り替えも可能になったという。
ソフトバンクとAmpereは今後、これらの成果を生かし、AIエージェント向けに複数のモデルを動的に切り替えながら、TPS(Tokens Per Second:1秒当たりのトークン出力数)を安定的に維持できるAI推論プラットフォームの実現に向けた取り組みを進めていくとしている。