「世界モデル」の中でAIが想像・予測
川本氏によれば、この数年で「動きの作り方」にも世代交代が見られるという。「考える脳と動く脳を分ける設計が主流になってきている」とし、これによって人間に近い、滑らかかつ正確な動作が可能になってきている。
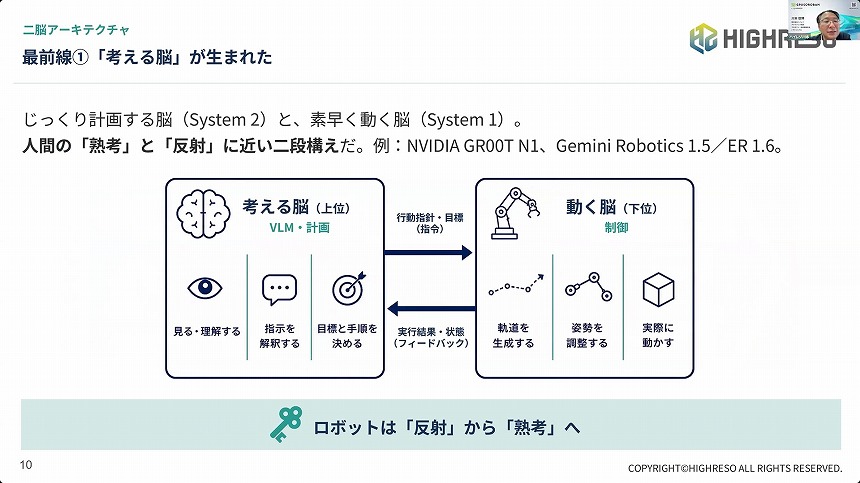
二脳アーキテクチャによる分業のイメージ
これを含め、最新のAI研究では「考える」「経験から学ぶ」「想像する」という3能力の統合が進んでいると川本氏は解説した。
「考える」能力は、計画を立てる脳と素早く体を動かす脳の二段構えにより、複雑なタスクを実行する。そして、「経験から学ぶ」能力によって、人の手本を真似るだけでなく、自ら試行錯誤して上達することができるようになる。
さらに、「想像する」能力によって、AIは「世界モデル」と呼ばれるシミュレーターを持ち、“こう動いたら、こうなるはずだ”と行動前に結果を予測することが可能になる。これら3能力の統合によって、AIは人間の認知を一通り獲得する。これが、未知の環境やタスクで使えるフィジカルAIに現実味が出てきた理由だ。
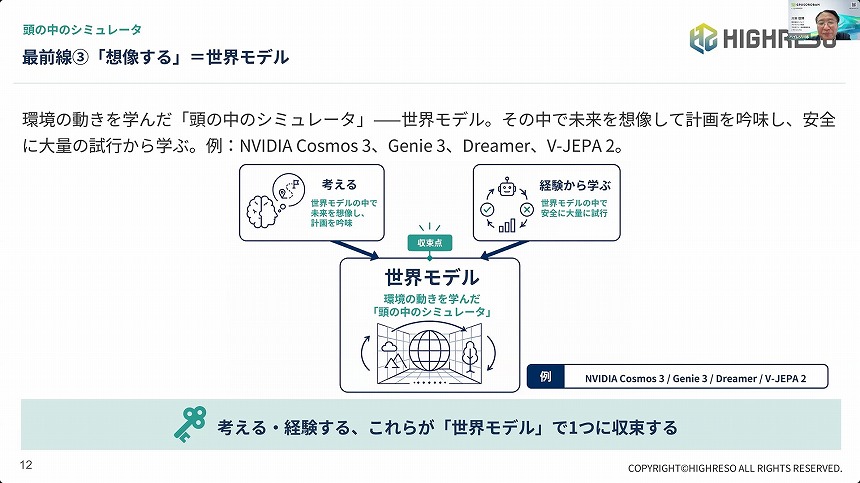
世界モデルに「考える」「経験から学ぶ」能力を統合
巨大化する「作るGPU」
しかし、その代償として、AIを作るのにも動かすのにも膨大なGPUが必要になった。
川本氏は、フィジカルAIに必要なGPUは、現場のデバイスで即座に判断を下す「動かすGPU(推論用)」と、クラウド上で膨大なデータから知能を作り出す「作るGPU(学習用)」の2種類に分かれると説明。そのうえで、後者は桁違いの規模へと巨大化している現状を紹介した。
実例として、オープンソースのVLAモデルである「OpenVLA」の学習には「人がロボットを操作して集めた約97万件の動作データを、64台のGPUで15日間連続稼働させる必要がある」。これでも中規模レベルであり、最新の大規模モデルでは、さらに1~2桁多くのGPUが必要になっているという。
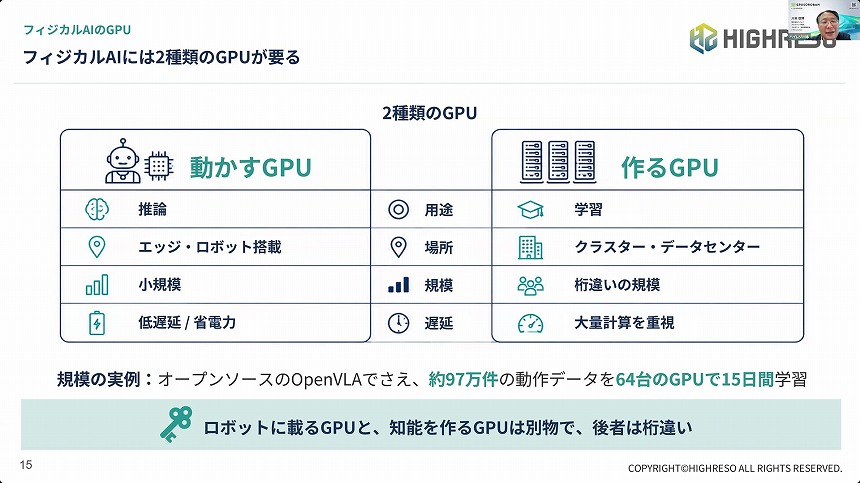
フィジカルAIには2種類のGPUが必要
また、GPUの高密度化によりデータセンターの消費電力は1ラックあたり100kW超に到達。次世代では200kW超に達し、液体冷却が不可欠となっている。
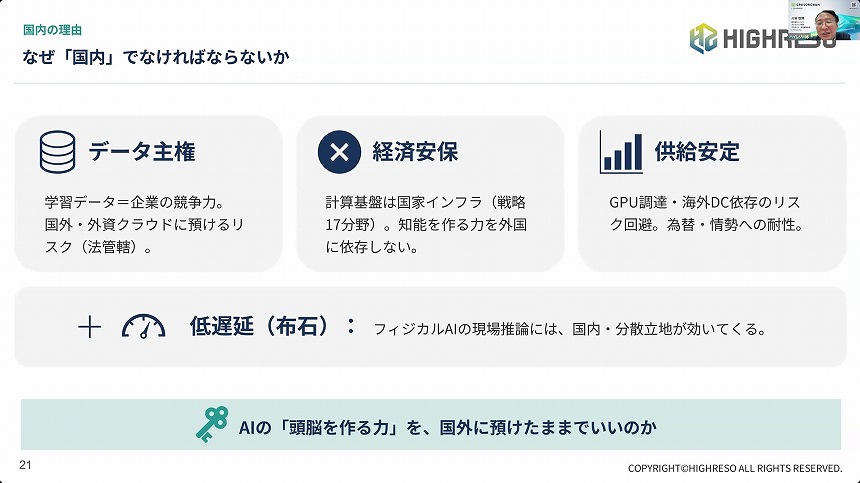
なぜ、国内でなければならないのか
こうした状況の中、「作るGPU」の置き場所をめぐって様々な問題が浮上している。
1つは、もはや個社では持てないレベルにまで巨大化していること。数百から数千のGPUを数週~数カ月フル稼働させるためには、巨額の投資と年単位の準備期間がかかる。さらに、AI学習の需要は変動するため、どうしても遊休期間が増える。そのため、川本氏は「所有するのではなく、必要な時に必要なだけ使う」のが現実解だと強調した。
GPUインフラが「国内」でなければならない理由
もう1つの問題はデータ主権だ。「AIを学習させるデータは、その企業の競争力そのものになる。それを海外資本のクラウドに預けてしまっていいのか、法律上どの国の管轄になるのかという問題もある」と同氏は指摘した。
経済安全保障の観点から、知能を作る力を外国に依存せず国内で整備することは重要だ。計算リソースの供給安定、為替・国際情勢への耐性強化にもつながる。また、動かすGPUについても、国内に分散立地することは、低遅延に現場推論を実行できるというメリットをもたらす。
こうした理由から、川本氏は、国内のGPUクラウドの整備と活用が必要だと訴えた。ハイレゾは国内の自社データセンターでGPUを提供するサービス「GPUSOROBAQN」を展開。国産の学習基盤の整備を事業の軸に据えている。
フィジカルAIはすでに、概念整理の段階から実装フェーズへと移行しつつある。技術の成熟と人手不足の深刻化、そして国家戦略という3つの力が交差するこの領域の動向に、引き続き注視しておきたい。


























