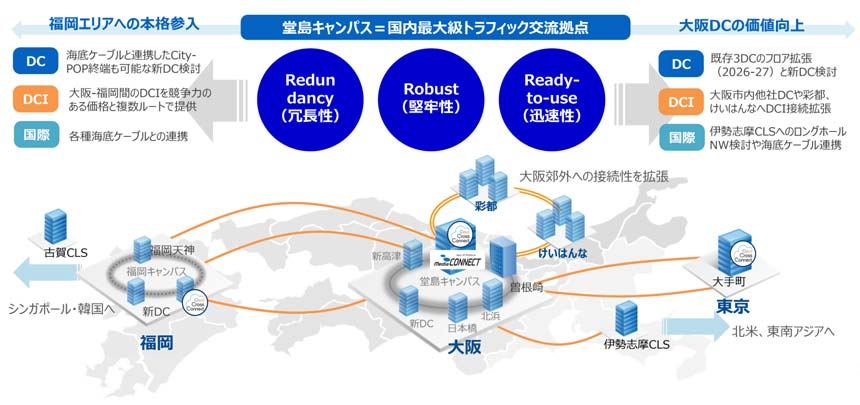
AIデータセンターでは数千本から数万本もの光トランシーバーモジュールが使われているが、そのうち1本が故障した場合の損害はどれほどになるか。
「400Gならモジュール1本当たり10万円、800Gで数十万円…」と考えるのは、残念ながら的外れだ。光トランシーバー1本の故障は、AIインフラ全体の稼働率に大きく影響する。GPUカードが1万枚規模の大規模GPUクラスターでは、学習停止が発生した場合、1日当たり数千万円規模の機会損失につながる可能性があると指摘する調査もある。
業界平均で3~4日に1回障害発生もファーウェイは故障率50%低減
莫大な経済損失を生む理由は、AI学習の「中断」にある。
AIのトレーニングは、多数のGPUで大量のデータを分散処理し、結果を集めてまた分散処理するという動作を繰り返す。GPU同士が通信する間は処理が止まりアイドル状態となるので、できるだけ広帯域な通信を行うことが大前提になる。AIデータセンターで400G/800G光伝送が主流となっているのはそのためだ。もちろん、通信遅延も少なければ少ないほどよい。
パケットロスも厳禁だ。再送処理の間、他のすべてのGPUが待たされる。最も遅い1台に他の全GPUが合わせることになるのだ。まして、通信が途絶してAI学習が異常中断すれば、学習処理がやり直しになる可能性もある。
だから、AIデータセンターの運用者は光トランシーバーの故障をできるだけなくしたいのだが、数が多いためそれもままならないのが現状だ。
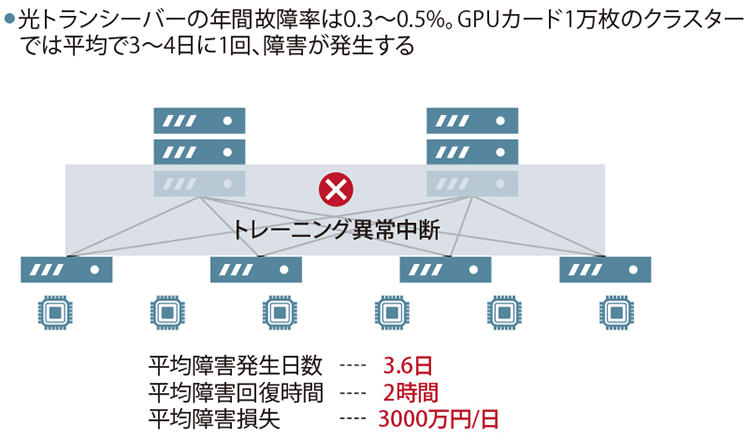
今や、数千基のGPUを接続する大規模クラスターも珍しくない。GPUが1千基なら光トランシーバーは2500~4000本、1万基なら2万5000~4万本にも達する。一般に、データセンター向け光トランシーバーの年間故障率は約0.3~0.5%程度とされているため、1千基のGPUクラスターなら8日に1回、1万基規模では、理論上は平均して3~4日に1回程度、何らかの光トランシーバー障害が発生し得る計算になる(図表1)。
図表1 光トランシーバーの故障によるAIトレーニングの中断
GPUクラスターの規模は今も拡大中で、光トランシーバーの本数が減ることは当面考えにくい。であれば、故障しにくい光トランシーバーこそが求められる。
この市場の要請に応えているのが、ファーウェイだ。ファーウェイ・ジャパン(華為技術日本) ICTマーケティング&ソリューション・セールス部 ネットワークソリューション・セールス部 部長の陶堯氏によれば、ファーウェイ製光トランシーバーは、同社の実運用データに基づき、故障率0.1%台を維持しており、一般的に言われる水準を大きく下回っているという。加えて、伝送性能の高さと安価なコストが支持され、スイッチメーカー純正の光トランシーバーに代えて、ファーウェイ製が採用されるケースが増えてきているという。