楽天グループは2024年3月21日、日本語に最適化した大規模言語モデル(LLM)を公開した。
公開したのは、LLMの基盤モデル「Rakuten AI 7B」のほか、同モデルを基に利用者が入力した指示に対して返答を生成できるようにしたインストラクションチューニング済みモデル「Rakuten AI 7B Instruct」と、それをさらに会話形式で質問への返答をできるようにファインチューニングしたチャットモデル「Rakuten AI 7B Chat」の3モデル。いずれもApache 2.0ライセンスによるオープンなモデルとして公開されており、楽天の公式「Hugging Face」リポジトリからダウンロードが可能だ。
基盤モデルの開発は、フランスのAIスタートアップ・Mistral AI社のオープンモデル「Mistral-7B-v0.1」を基に、インターネット上の日本語・英語のデータを学習することで行われた。パラメータのサイズは70億。事前学習は、楽天が設計した内製のマルチノードGPUクラスターで行われた。条件に従ったフィルタリングと関連情報の付与を行ったデータで事前学習を行っていることが、LLMの性能の高さに寄与しているという。
また、同LLMは日本語に最適化された独自の形態素解析器を用いることにより、従来の形態素解析器と比較して事前学習や推論のテキスト処理をより効率的に行えるようになったとしている。
基盤モデルとインストラクションチューニング済モデルは、言語モデル評価ツール「LM Evaluation Harness」の基準において、日本語と英語ともに高く評価されたという。日本語は、基盤モデルが平均69.8ポイント、インストラクションチューニング済モデルが平均77.3ポイント、英語は、基盤モデルが平均60.5ポイント、インストラクションチューニング済モデルが平均61.3ポイントのスコアをそれぞれ獲得し、他のオープンな日本語LLMとしても優れているという。
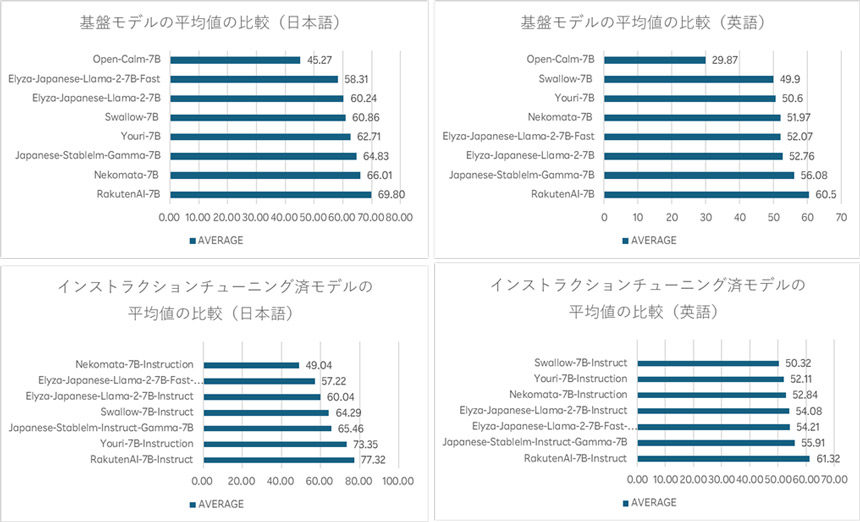
「LM Evaluation Harness」におけるモデルの評価
楽天は、社内でLLMを開発することで、楽天経済圏をサポートするための最適化されたモデル作成を目指していくとしている。