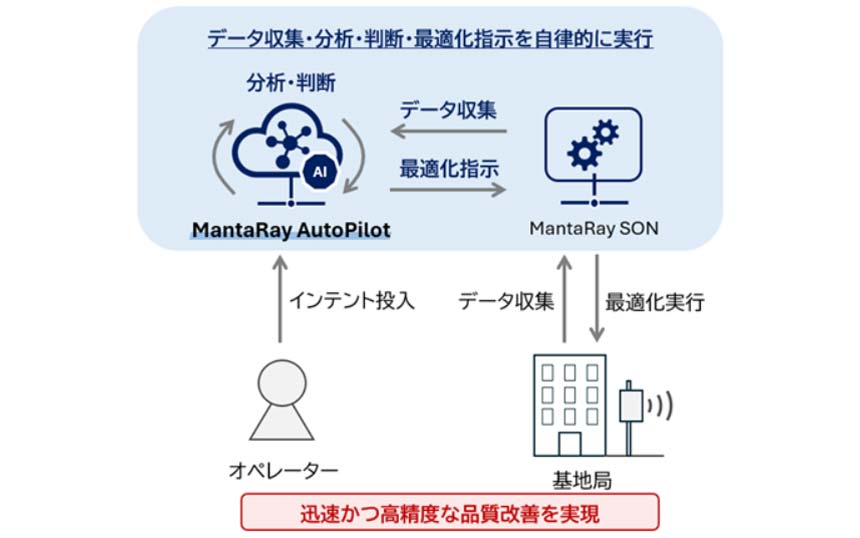
AIの学習では、多数のGPUで分散して処理を走らせ、その結果を集めてまた分散処理する動作を繰り返す。GPU間で通信する間はGPUはアイドル状態となる。これをいかに減らして効率的に利用するかが問われることになる。
また、GPUをつなぐRDMA(Remote Direct Memory Access)はパケットロスに敏感なため、より安定したネットワークが必要だ。ある調査によれば、AIのタスクが失敗する原因の20%以上がネットワークの問題に起因するとも言われている。日本ヒューレット・パッカード HPE Networking 事業統括本部の塚本広海氏は、「AIインフラ、GPUのインフラではネットワークのパフォーマンスが非常に重要。エラーがなく安定したネットワークをいかに提供し、AIのポテンシャルを解放できるかが求められている」と話す。

日本ヒューレット・パッカード HPE Networking事業統括本部 技術本部 テクノロジーコンサルティング部 部長 塚本広海氏
HPEのジュニパーネットワークス買収・統合により誕生したHPE Networkingは、旧ジュニパー時代からこのミッションを追求してきた。2025年の統合完了後も、AIを駆使してネットワークの運用を最適化する「AI for Network Ops」と、GPU間の接続をはじめ、AIに最適なインフラを利用することができる「Networks for AI Workloads」の2軸で、製品を開発・強化。幅広いポートフォリオを展開している。
AIを取り巻く技術要素に合わせ進化を続けるネットワーク製品群
2025年12月に開催された「HPE Discover Barcelona 2025」では、Networks for AIを加速させる新製品群が発表された。
最大の目玉は、102.4Tbpsの容量を備える「QFX5250」スイッチだ。最大で1.6Tbps×64ポートをサポートするBroadcom Tomahawk 6を搭載した初のデータセンタースイッチである。国内ではサイバーエージェントがAIデータセンターで採用している800G対応スイッチ「QFX5240」の上位機種に当たる。

Broadcom Tomahawk 6を搭載した「QFX5250」スイッチ。102.4Tbpsのキャパシティと、100%液冷設計が特徴だ
Tomahawk 6の採用によりベンダーロックインの恐れがなく、トラブルシューティングが容易で、しかもUltra Ethernet Transportに対応することで高いパフォーマンスを実現した。輻輳制御技術であるDCQCN、Dynamic Load Balancing(DLB:動的負荷分散)やGlobal Load Balancing(GLB:広域負荷分散)、RDMA-aware Load Balancing(RLB:RDMA対応負荷分散)といった輻輳回避技術をサポートし、パケットロスを極力出さないようにしている。
「GPUをはじめ、AIインフラを取り巻く技術はめざましい勢いで進化している。GPU基盤には、非常に広帯域であるだけでなく、パケットロスを起こさないような輻輳回避技術を備え、さらに全体の状況を把握してパフォーマンスを最適化するようなネットワークが求められている」と塚本氏。QFX5240とQFX5250はそれらを満たす製品であり、GPUサーバーを追加することで横に拡張していくスケールアウトにも対応する。
また、QFX5250にはもう1つ、同社ならではの特徴がある。HPEが強みとしてきたサーバーの液冷技術を活用し、100%水冷を実現している。