NTTコミュニケーションズ(NTT Com)は2024年11月22日、同社が提供する通信型ドライブレコーダーサービス「LINKEETH」をタイで販売開始した。NTT Comのグループ会社であるモバイルイノベーションが提供する。
本サービスは、位置情報を使った車両の運行管理や、運転データの分析による安全運転診断を行うもの。
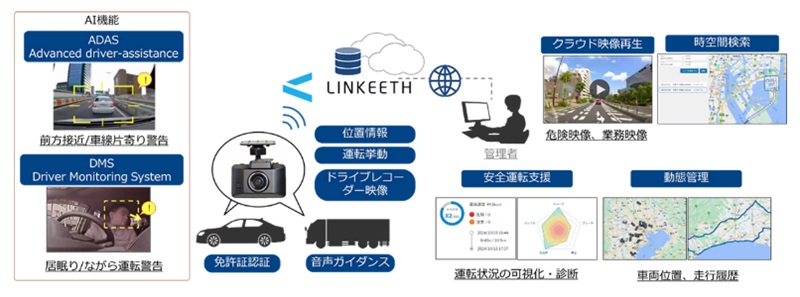
ADAS(Advanced driver-assistance systems)およびDMS(Driver Monitoring System)機能に関しては、車両に搭載されたカメラの映像を元にAIが運転状態を監視し、危険な運転を検知するとドライバーへ警告することで事故を未然に防ぐ。
また、加速やブレーキ、ハンドル操作、スピードなどの運転データを分析し、ドライバーの運転のクセを可視化。診断結果のレポートは安全運転指導に役立つ。
事故や危険な運転を検知した際には、映像データをクラウドへ自動送信し、登録された宛先へメールで通知する。また、任意のタイミングでリアルタイムおよび過去の映像をリモートから確認することも可能だ。
今回のタイでの提供開始に続き、NTT Comとモバイルイノベーションでは、インドネシアでの展開も予定している。また、タイのオートリース会社であるSumitomo Mitsui Auto Leasing & Service(Thailand)が、本サービスを利用した新しいオートリースの提供を予定しているという。