「我々は多くのエネルギーを注いで、光ファイバーセンシングソリューションの研究開発を進めてきました。世界各地で様々なベンダーが開発を手掛けていますが、その中で最も幅広く採用されているのが、ファーウェイの『OptiXsense』です」。こう自信を見せるのは、ファーウェイ・ジャパン 光技術ソリューションセールス部 部長の曾小虎氏だ。
光ファイバーセンシングとは、光ファイバーを「センサー」として用い、振動や温度、ひずみなどの物理量の変化を検知・計測する技術だ。光ファイバーに光を送り込み、戻ってくる光(散乱光)の変化を観測することで、状態変化を把握するのが基本的な仕組みである。
長距離に敷設された光ファイバー自体がセンサーとして機能するため、スポット的にIoTセンサーを設置する場合と比べ、広範囲を連続的にセンシングできる点が特徴だ。また、光ファイバーは電気を通さないため、落雷や電磁干渉の影響を受けにくく、適切に施工・保守されていれば20年以上の長期運用が可能な高い耐久性も備える。
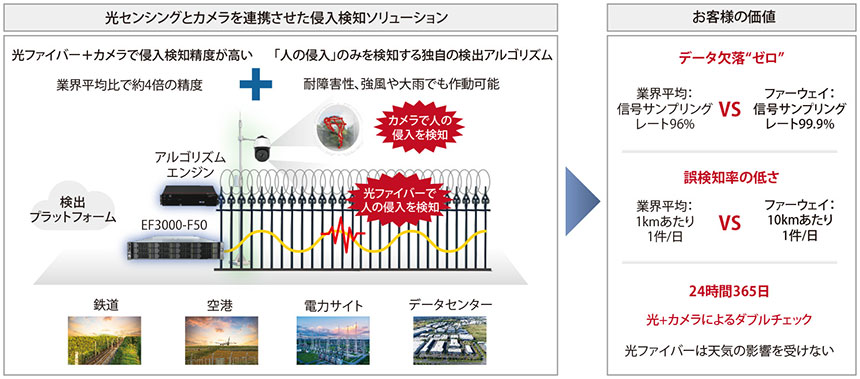
では、光ファイバーセンシングソリューションを展開するベンダーが数多く存在するなかで、ファーウェイのOptiXsenseが選ばれる理由はどこにあるのだろうか。それは、光ファイバーとカメラを組み合わせた「圧倒的な誤検知率の低さ」にある。
具体的には、同社が開発した光ファイバーセンシング装置「EF3000-F50」とカメラを連携させた構成だ。これにより、「センサーだけでは面的なセンシングが難しい」「光ファイバー単体では十分な精度が得られない」といったユーザー企業が抱える悩みを解決する。

OptiXsenseの特徴はこれだけではない。ファーウェイならではの技術が随所に盛り込まれている。
その1つが、DSP(デジタル信号処理)モジュールの活用だ。「散乱光に含まれるノイズやゆらぎを抑え、信号品質をクリアにできます。40年近く開発してきた、光の位相や偏波を使って大容量化・長距離化を実現する『デジタルコヒーレント技術』を光ファイバーセンシングにも応用しています」と同社 プロフェッショナルサービス部 シニアエンジニアの坂田智氏は語る。
このDSPモジュールなどの活用により、散乱光から必要な情報をどれだけ欠落なく取得できるかを示す指標である「信号サンプリングレート」は99.9%に達するというから驚きだ。「信号サンプリングレートの業界水準は96%程度。他社と比べて大きな優位性があります」と光技術ソリューションセールス部 ソリューションマネージャーの杜豊寧氏はアピールする。
もう1つ見逃せない技術が、ファーウェイ独自の検知アルゴリズム「IDF-AD」である。例えば人の侵入を検知するユースケースでは、風や雨などの環境要因による振動を識別・除外し、人の侵入に由来する振動のみを抽出できるという。この技術も、“誤検知率ほぼゼロ”の実現に大きく寄与している。
光ファイバーやカメラが人の侵入を検知した場合には、アラームの発報や現場の映像データを警備室などに通知することも可能だ。なお、OptiXsenseの導入には、センシング装置やカメラに加え、光ファイバーセンシング用の管理プラットフォームやカメラ用のレコーダーなどの装置も必要になるが、「約5kmの範囲をカバーするケースで、光ファイバーがすでに敷設されていれば、半日程度で工事が完了します」と杜氏は導入の容易さを強調する。
図表 ファーウェイの光ファイバーセンシング「OptiXsense」の概要